
Ⅰ. 분석에 필요한 사항 준비
[인사-23005] 직무급 연구 : 직무평가와 군집분석의 활용 ①
Ⅰ. 직무급 도입과 직무평가등급 설정의 어려움 필자의 아버지는 "돈을 벌지 못할 것처럼 보이는 직무가 오히려 돈을 많이 버는 경우가 상당히 있으니 직무를 평가하는데에 있어 겉모습만 보지
laborlawseok.tistory.com
위 링크에서 설명한 대로 이제부터는 실전에 돌입하겠다!
지금까지는 파이썬을 통해서 여러가지 분석을 시도하였지만 이번에는 R언어를 활용하고자 한다. 인공지능이나 자연어 처리가 필요한 경우에는 대부분 파이썬을 사용하지만 그 외에 통계분석 등 정형화된 데이터를 처리해야 하는 경우엔 R언어를 많이 사용한다.
따라서 HR 데이터 분석가라면 양 언어를 어느 정도 숙지할 필요가 있다!(물론, 필자도 R언어 베이스라 파이썬이 그렇게 익숙하지 않다. 하지만 우리에게 Chat-GPT 선생님이 계시니 너무 걱정할 필요가 없다.)
우선, R언어 역시 파이썬과 마찬가지로 프로그램 설치가 사전에 필요하다. 이제부턴 어려운 용어는 전부 빼고 필요한 내용만 전달하고자 한다. 우리에게 필요한 프로그램은 ①R과 ②R Studio이다. 이 두가지 프로그램을 다운로드 받는 것은 그다지 어려운 일이 아니므로 아래 참고할 수 있는 링크를 남겨두겠다. 아래 링크에서 두 가지 프로그램을 다운로드 받고 다시 돌아오길 바란다.
R과 R 스튜디오(R Studio) 설치 방법(윈도우)
R은 통계 분석에 특화된 프로그래밍 언어로, 데이터 분석 시 많이 사용합니다. 프로그래밍 언어는 사용자가 직접 모든 걸 명령어로 입력하고 실행해야 하므로 상당히 불편합니다.이때 필요한 것
hongong.hanbit.co.kr
필요한 프로그램을 모두 설치하였다면 R Studio를 실행시켜서 아래의 그림과 같이 "도화지"를 준비하자. "도화지"란 여러분들이 코드를 작성할 흰색 화면을 말한다.

위 절차대로 한다면 코드를 작성할 수 있는 Script 화면이 나타날 것이다.
이제 그 Script 창을 클릭해서 1+1을 입력해보라. 그럼 다음과 같이 작성될 것이다.
1 + 1이 입력된 곳을 아무대나 클릭한 후 Ctrl + Enter를 동시에 누르면 해당 줄에 있는 코드가 실행된다. R Studio는 이런 식으로 구동된다고 보면 된다. 지면상 R 언어에 대해 기초적인 부분까지 설명할 수 없으므로 여러분들이 나머지는 찾아서 공부할 필요가 있다.
우리는 다음 단계인 "그럼 어떻게 직무평가등급을 분석할 건데?"라는 물음에 정량적으로 답해보려고 한다.
가보자!
Ⅱ. 수집된 직무평가 데이터의 형태 확인
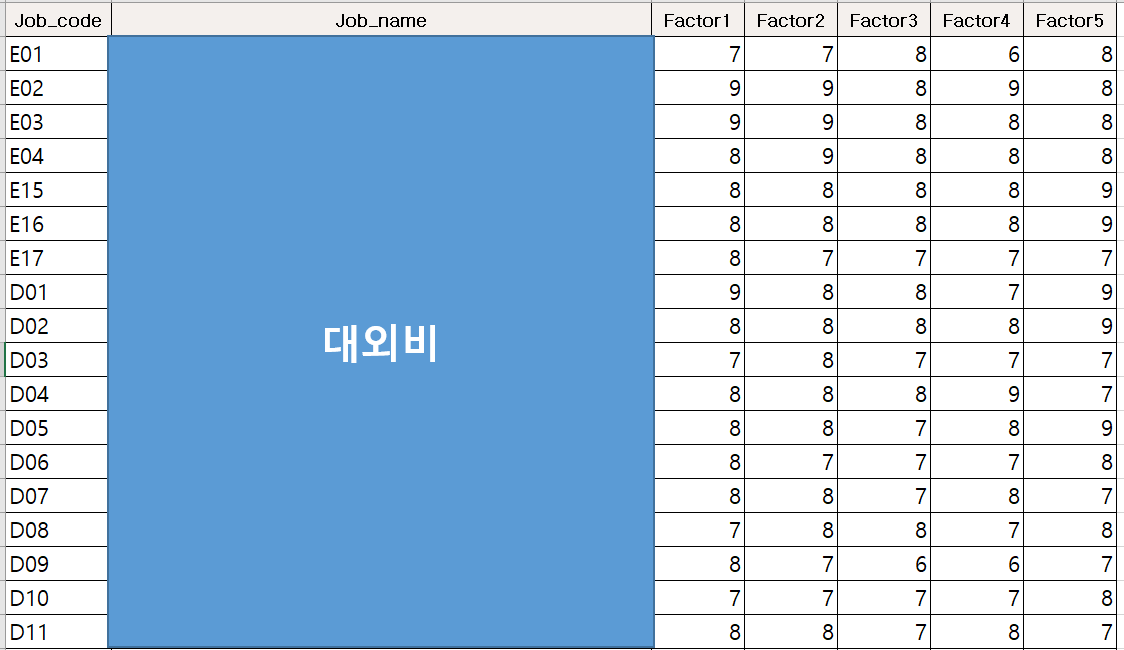
직무평가 데이터는 위 이미지와 같이 엑셀로 수집한다. 각 직무별로 Job_code를 설정하고, Job_code가 의미하는 바를 간단하게 표시해둔다. 상기 자료에서는 직위 수준을 알파벳으로 표현하였다. Factor1부터 Factor5까지는 직무평가요소를 의미한다. 각 요소별로 10점 척도(물론, 이러한 척도의 타당성을 고민하는 독자도 있을 것이다. 이와 관련된 내용은 내용이 생각보다 깊어 다음 인사 이야기의 주제로 들려드리겠다.)를 활용하여 직무평가자들로부터 점수를 취합받은 엑셀 자료라고 보면된다.
따라서 각 직무별로 평가자 수만큼의 직무평가 점수 데이터가 수집되어 있다고 생각하면 된다. 분석할 때 가장 중요한 것은 ①내가 어떤 목적 하에서 이러한 작업을 하는지, ②그 작업을 위해 내가 어떤 분석 기법을 적용할 것인지, 그리고 ③그 분석 기법에 적합한 데이터의 형태는 어떤 구조인지를 고민하면서 데이터를 수집하는 것이 중요하다. 인사기획 또는 조직문화 관련 설문조사를 배포할 때에도 마찬가지임을 잊지 말자!
향후 직무분석, 직무평가, 직무급 설계와 관련된 주제로 글을 추가로 작성할 예정이다. 향후 작성 예정인 글에서 어떻게 이러한 직무평가 데이터를 확보할 수 있는지 구체적으로 기술해보고자 한다.(조금만 기다려 주세요..!)
오늘은 R 코드 설명에 좀 더 집중하겠다..!
Ⅲ. 직무평가등급 추정_R Code
1. 필요한 패키지 다운로드 및 불러오기
## Download packages
install.packages("tidyverse")
install.packages("readxl")
install.packages("fpc")
install.packages("factoextra")
install.packages("dendextend")
install.packages("cluster")
install.packages("NbClust")
install.packages("kableExtra")우선 분석에 필요한 패키지들을 다운로드 받아야 한다. 다운로드 받는 방법은 "install.packages("패키지명")"이라고 입력하면된다. tidyverse는 기초적인 분석을 용이하게 만들어주는 도구이다. readxl은 엑셀 데이터를 R 프로그램 분석 환경에 임포트 시키는 역할을 한다. fpc부터 Nbclust까지는 군집분석과 관련된 패키지들이다. 자세한 것은 차차 코드를 설명하면서 함께 알 수 있다. kableExtra는 R markdown 보고서(데이터 분석 시각화 보고서)를 작성할 때 데이터 프레임에 들어있는 내용물을 쉽게 볼 수 있도록 만들어준다.
※ 참고로 우리가 사용하는 도화지는 단순히 R Script 도화지이지만, 향후 R markdown 보고서를 작성하여 시각화된 분석 보고서를 작성할 수도 있으므로 코드는 R markdown 보고서 용으로 소개하겠다.
패키지들이 전부 다운로드가 완료되었다면 이러한 패키지들을 이번 분석에 사용하겠다고 컴퓨터에게 미리 선언해주어야 한다. 선언하는 방법은 "library(패키지명)"이다. 구체적인 코드는 다음과 같다.
## loading packages
library(tidyverse)
library(readxl)
library(ggplot2)
library(fpc)
library(factoextra)
library(dendextend)
library(cluster)
library(NbClust)
library(kableExtra)2. 데이터 준비 및 전처리
###Data Import & Prepare
Raw_data = read_excel("수집된 직무평가데이터명.xlsx")
management = Raw_data %>% ## 실장~팀장급 직무 데이터 준비
filter(str_detect(Job_code, 'D|E')) %>%
group_by(Job_code) %>%
summarise(Mean_F1 = mean(Factor1),
Mean_F2 = mean(Factor2),
Mean_F3 = mean(Factor3),
Mean_F4 = mean(Factor4),
Mean_F5 = mean(Factor5))
name = management[,1]
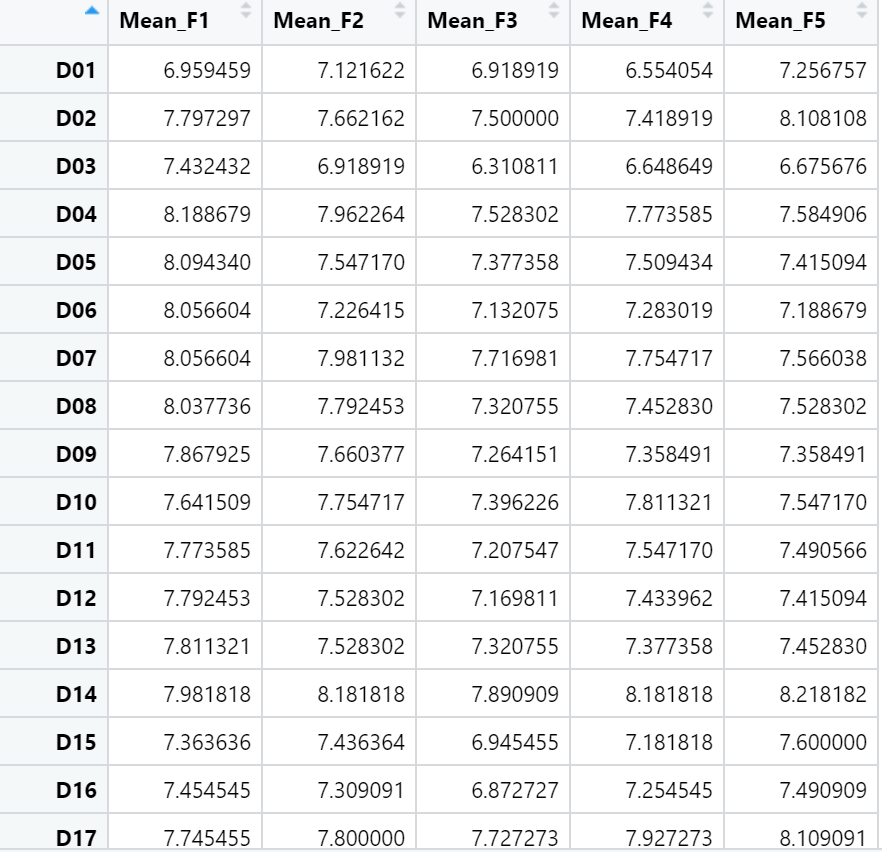
DF = data.frame(management[,-1], row.names = name$Job_code) ## 행 인덱스 지정이제 우리는 분석에 필요한 데이터(음식 재료)를 우리의 분석환경이라는 도마에 올려야 한다. 앞서 수집한 직무평가 데이터를 바탕화면에 옮겨놓고 read_excel함수를 사용해 Raw_data라는 이름의 데이터 프레임으로 데이터를 가져오자.
이번 과제에서는 보직자들의 직무평가등급을 분석하는 것이므로 ①보직자들만 데이터를 추출하여 ②직무별로 묶어주되 ③개별 직무평가자들이 입력한 요소별 직무평가 점수의 평균으로 정리하여 mangement라는 이름으로 전처리된 데이터를 입력하고자 한다.
※ 데이터 전처리란 도마 위에 올린 음식 재료를 제작할 음식에 맞게 손질해두는 것이라고 생각하면 된다.
- 보직자들만 데이터를 추출 : filter(str_detect(Job_code, 'D|E'))
- 직무별로 묶음 : group_by(Job_code)
- 요소별 직무평가 점수의 평균으로 정리 : summarise(Mean_F1 = mean(Factor1) ··· 생략)
이렇게 management의 값이 입력되면 이를 군집분석에 맞는 데이터로 전처리할 필요가 있다. 군집분석에는 행 인덱스가 지정될 필요가 있어 행 이름으로 직무들의 이름인 직무코드(Job Code)가 입력되어야 한다. 그러한 작업을 다 완료하면 우리가 군집분석에 활용할 "DF"라는 최종적인 분석 데이터가 완성된다.
3. 표준화 거리 지정 및 군집화 방법 지정
Dis = dist(DF, method = "minkowski", p = ncol(DF)-1) # 표준화 거리 지정
hc = hclust(Dis, method = "ward.D") # 군집화 방법 : ward 통계량 근거첫 번째 글에서 설명한 바와 같이 군집분석에 활용할 거리값을 설정해야 하는데, 우리는 민코프스키 거리를 이용하였다. P값(어떤 자료에서는 'M'이라고 불린다.)은 [변수 개수 -1]로 지정하였는데, 사실 P값에 2를 집어넣어 유클리드 거리로 계산하여도 무방할 것으로 보인다. 필자는 당시 변수의 개수가 5개이고 척도가 10점 척도라 단순히 유클리드 거리로 계산할 때보다 일반화된 거리로 계산하는 것이 바람직할 것이라 판단하였기에 상기와 같이 설정한 것이다.
군집화 방식은 ward 법을 이용하였다. ward 법을 통해 계층적 군집분석을 실시한 결과와 k-means 군집분석의 결과는 거의 95% 이상 동일하므로 별도로 k-means 군집분석을 돌리지 않을 것이기에 해당 방법을 채택하였다. 여기서의 자세한 설명은 맨 위 링크에서 살펴보았으니 해당 글을 참고하길 바란다.
4. 적정 군집의 개수 파악 : Nb Clust 패키지 활용
Optimize_Clust = NbClust(DF, distance="minkowski", min.nc=3, max.nc=20, method="ward.D")Nb Clust는 적정 군집의 개수를 판단하는 지표로서 여러 학자들이 생각하는 적정 군집의 수를 제시해준다. 이 역시 자세한 이야기는 앞서 참조한 링크를 참고해주기 바란다. 위 코드를 풀이하면 다음과 같다.
1. 약 20명 정도의 학자들에게 "DF" 데이터에 대한 적정 군집의 개수를 알려달라고 요청하되,
2. 이를 판단하기 위하여 "민코프스키 거리"와 "와드법"을 이용하고,
3. 최대 20개에서 최소 3개 이상의 군집 개수 범위 내에서 시뮬레이션 돌려줘!
코드만 봐도 대충 무슨 말을 하는지 감이 오지 않는가..? 상기 식을 실행시키면 다음과 같은 결과가 나타난다.
The Hubert index is a graphical method of determining the number of clusters. In the plot of Hubert index, we seek a significant knee that corresponds to a significant increase of the value of the measure i.e the significant peak in Hubert index second differences plot. *** : The D index is a graphical method of determining the number of clusters. In the plot of D index, we seek a significant knee (the significant peak in Dindex second differences plot) that corresponds to a significant increase of the value of the measure.
*******************************************************************
* Among all indices:
* 7 proposed 3 as the best number of clusters
* 11 proposed 4 as the best number of clusters
* 1 proposed 5 as the best number of clusters
* 1 proposed 19 as the best number of clusters
* 3 proposed 20 as the best number of clusters
***** Conclusion ****** According to the majority rule, the best number of clusters is 4
*******************************************************************
11개의 지표가 4개의 군집이 적절하다고 판단하였으므로 DF 내 직무평가 데이터에 대한 직무평가 등급의 수(군집의 수)는 4개일 가능성이 높아진 것이다. 여기서 4개라고 단언하지 않는 이유는 데이터 분석을 맹신하지 않기 때문이다. 분석 결과 역시 가정과 분석자의 주관이 어느정도 개입한 것이므로 그대로 신뢰할 수 없으며 군집의 수가 3개일 경우와 5개일 경우도 함께 1안, 2안, 3안으로 고려는 하고 있어야 한다.(데이터 분석은 의사결정을 "도와주는 역할"이지, "의사결정자의 역할"을 대신할 수 없다.)
※ 구체적으로 어떤 지표들이 몇 개의 군집이 적정하다고 판단하였는지 구체적으로 살펴보고 싶다면 아래의 코드를 실행시키면 된다. 참고하시면 좋겠다.
Table: 지표별 지지하는 군집의 개수
Number_clusters Value_Index ----------- ---------------- ------------
KL 4 4.1361
CH 4 96.9272
Hartigan 4 18.4046
CCC 3 34.5549
Scott 4 70.5185
Marriot 4 585.9935
TrCovW 4 3.4324
TraceW 4 4.3781
Friedman 19 1892.9947
Rubin 4 -161.0903
Cindex 20 0.2778
DB 3 0.9144
Silhouette 3 0.3694
Duda 4 0.3923
PseudoT2 4 17.0390
Beale 5 1.7560
Ratkowsky 3 0.4779
Ball 4 3.7696
PtBiserial 3 0.5728
Frey 2 NA
McClain 3 0.6909
Dunn 20 0.2612
Hubert 0 0.0000
SDindex 3 4.9861
Dindex 0 0.0000
SDbw 20 0.0707
5. 군집분석 시각화 : 덴드로그램(Dendrogram)
fviz_dend(hc, k = 4, # Cut in three groups
cex = 0.8, # label size
color_labels_by_k = TRUE, # color labels by groups
ggtheme = theme_gray(), # Change theme
ylab = "거리"
)최적의 군집의 수가 4개라는 사실을 앞서 살펴보았으니 어떤 직무들이 함께 묶였는지 확인해볼 필요가 있다. fviz_dend는 k개의 군집으로 묶었을 때, 직무들이 어떻게 묶이는지를 덴드로그램이라는 그림으로 보고해주는 함수이다. 여기서 k를 4로 설정하였고 각 군집별로 다른 색상이 표시되도록 설정하였다. 이제 이 코드를 실행하고 그림을 살펴보자!
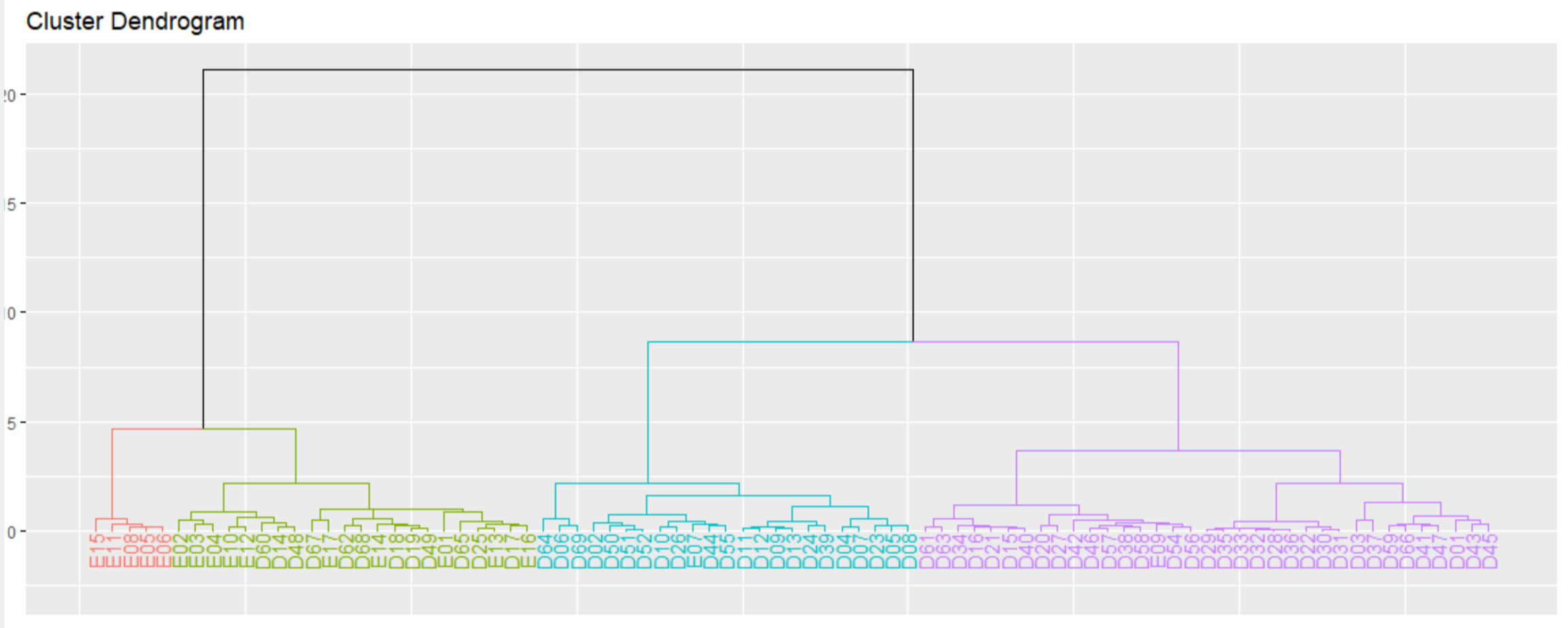
상기 그림은 덴드로그램이라는 군집분석 결과를 시각화하는 기법이다. Y축이 의미하는 것은 앞서 우리가 살펴본 민코프스키 거리이다. 두 직무의 거리가 가까울 수록 0에 수렴하고, 거리가 가깝다는 의미는 두 직무의 직무평가요소(직무의 성질)가 유사하다는 의미이다. 반대로 멀리 떨어져 있을 수록 Y축의 상단으로 올라간다. 각 군집별 거리감은 실선으로 표시되며, 실선이 상단으로 갈 수록 점점 이질적이라고 볼 수 있다.
상기 그림을 통해 우리는 4개의 군집으로 나눴을 때 각 군집별로 어떤 직무들이 서로 묶여 있는지 확인해볼 수 있다. 그림의 맨 밑에 E15, E11 등은 아까 살펴본 직무코드로서 직무를 의미한다.인사팀은 "한 군집 내 A라는 직무와 B라는 직무에 대하여 유사 또는 동일하게 처우하여도 무방한지?"를 기준으로 직무평가등급(군집)에 대한 직무 배정의 타당성을 확인해보아야 한다.
※ 좀 더 자세히 어떤 직무가 어떤 직무평가등급(군집)에 배정되었는지 확인하고 싶다면 아래의 코드를 실행시키면 된다.
cutree(hc, k=4)6. 군집별 직무의 성질 파악
### 데이터 정제
C_4 =HC_4 %>%
group_by(Cluster) %>%
summarise("직무평가요소1" = mean(Mean_F1),
"직무평가요소2" = mean(Mean_F2),
"직무평가요소3" = mean(Mean_F3),
"직무평가요소4" = mean(Mean_F4),
"직무평가요소5" = mean(Mean_F5))
### 데이터구조 변경
long_data_C4 <- pivot_longer(data=C_4, cols=-Cluster, names_to = 'Factor', values_to = 'characteristic')
### 시각화 및 데이터 보고
ggplot(long_data_C4, aes(x= Factor, y = characteristic, fill = reorder(factor(Cluster),characteristic)))+
geom_bar(stat = "identity", position = "dodge") +
scale_fill_discrete(name = "군집") +
theme(axis.title.y=element_blank(),
axis.title.x=element_blank())
C_4 %>% kable("pandoc", caption = "군집별 직무평가요소 평균점수")직무들이 잘 묶였는지는 인사팀이 직접 눈으로 판단할 수 있지만, 군집별로 직무평가요소의 평균을 계산하여 확인해볼 수도 있다. 『업종별 직무평가 도구개발(2018)』에서 K-means 군집분석을 계층적 군집분석 이후에 추가로 실시하는 이유도 각 군집별 특성을 파악하기 위함인데, 우리는 이 과정을 생략하고 곧바로 군집별 평균값을 계산하여 비교해보는 것이다. 왜 이렇게 하는 것인지는 상기 링크([인사-23005] 직무급 연구 : 직무평가와 군집분석의 활용 ①)에서 살펴보았으므로 자세한 설명을 생략하겠다.
상기 코드를 실행하면 다음과 같은 시각화 그래프가 나타난다.
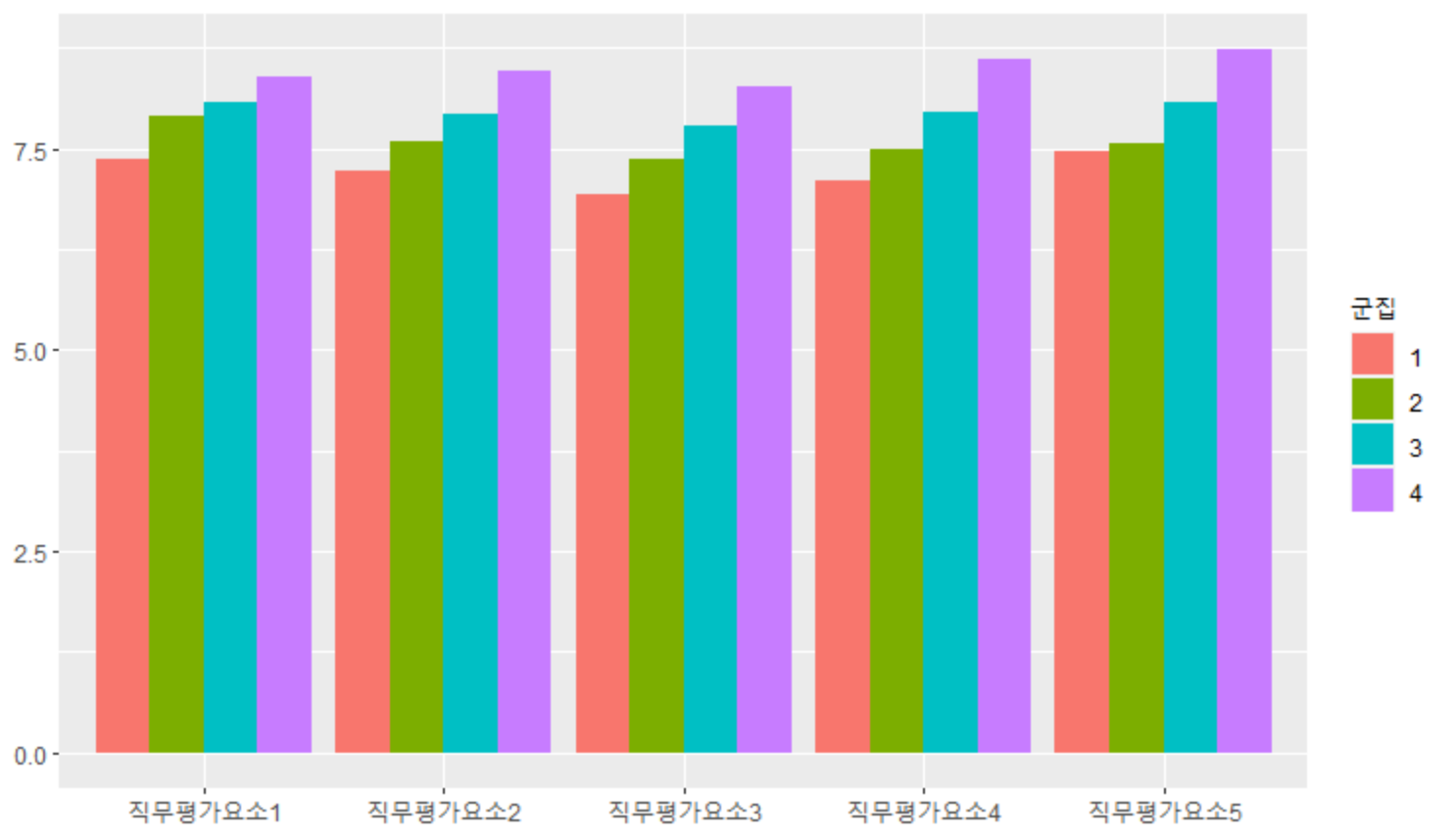
군집별로 각 평가요소의 뒤집힘 없이 예쁘게 분류가 잘 되었다. 1번 군집에서 대체로 직무평가요소별 점수들이 낮은 직무들이 배정되어 있는 것으로 파악해볼 수 있으며, 반대로 4번 군집에서 상당히 고도화된 직무들이 배정되어 있는 것으로 확인해볼 수 있다. 물론, 세부 직무별로 살펴보면서 최종적인 조정 작업이 필요하다.
7. 최종 직무평가등급 도출
## 직무별 군집 반영
hc_4 = as.vector(cutree(hc, k=4))
HC_4 = management %>%
mutate(Cluster = hc_4)
Average_4 = HC_4 %>%
mutate(Total_mean_Score = rowMeans(select(., 2:6)))
Average_4 <- Average_4 %>%
arrange(desc(Total_mean_Score)) %>%
mutate(RowNumber = row_number())
ggplot(Average_4, aes(x = RowNumber, y = Total_mean_Score, color = factor(Cluster))) +
geom_point(size = 1.5) +
theme(axis.line = element_blank(), axis.text.x = element_blank(), axis.text.y = element_blank(),
axis.ticks = element_blank(), axis.title.x = element_blank(), axis.title.y = element_blank()) +
scale_color_discrete(name="직무평가등급",
breaks=c(4,3,2,1),
labels=c("J4", "J3", "J2", "J1")) +
ggtitle("김 노무사와 즐거운 직무평가등급 분석")헉헉.. 이제 다 왔다..! 본 단계는 최종 직무평가등급을 설정하는 작업이다.
요즘 직무평가의 트렌드는 각 직무별 직무평가점수의 총점 또는 평균점을 기준으로 산포도를 그린 뒤, 적정 점수 구간을 정하는 것이다. 예를 들어 몇 점부터 몇 점까지는 제일 높은 직무등급, 몇 점부터 몇 점까지는 두 번째로 높은 직무등급 등을 정하고 이를 급여규정(또는 보수규정)과 같은 공식적인 취업규칙에 기재한다.
이때, 우리는 "무슨 근거로 적정 점수 구간을 설정할 것인가..?"라는 도전에 직면하게 된다. 기존의 직무평가 방법은 이 문제에 대한 답을 찾지 못하였지만, 우리는 지금까지 군집분석을 통해 직무별로 어떤 군집에 있었는지 분석하였기 때문에 답을 찾는데 근거를 제시할 수 있다. 앞서 말한 바와 같이 군집은 직무평가요소별로 그 성질이 유사한 직무들의 그룹이므로 군집에 근거하여 점수 구간을 탐색해볼 수 있는 것이다.
상기 코드를 실행시키면 아래와 같은 시각화 그래프가 나타난다.

위 그림의 점 하나는 직무를 의미하고, 색갈은 그것이 할당된 군집을 말한다. 직무별로 직무평가점수의 총 평균을 계산(이하 '직무평가 종합 결과'라 함.)하여 점 도표를 작성한 것인데, 직무평가 종합 결과가 높은 직무들은 군집 4번에 할당되어 있었으며 그 반대의 경우에는 군집 1번에 할당되어 있었다. 보시다시피 군집별 직무들이 살짝 살짝 섞여 있는 구간이 나타는데, 이곳이 바로 직무평가등급을 구분하는 우리의 의사결정이 필요한 포인트다. 이번 문단이 전반적으로 이해되지 않는다면 아래 그림을 보면 단박에 이해될 것이다.
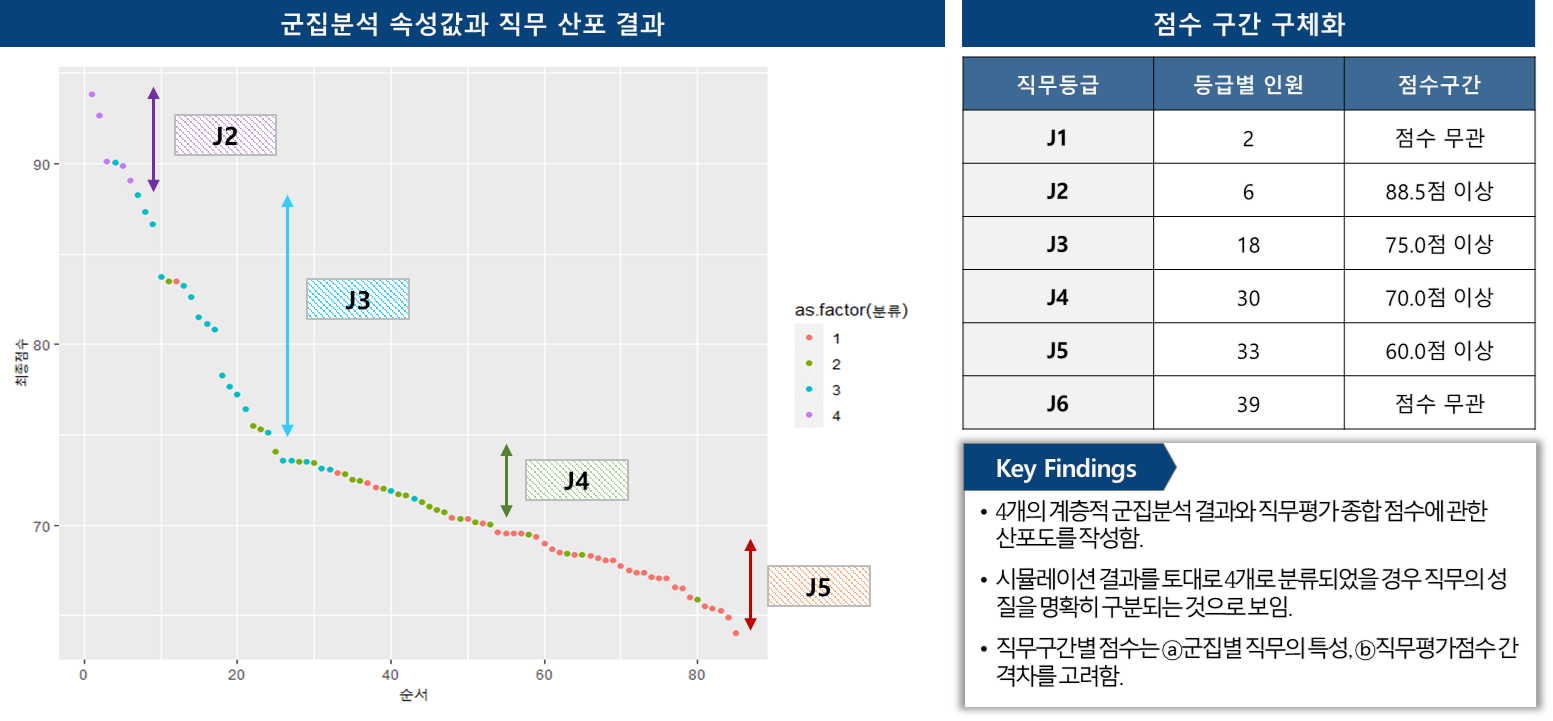
직무평가등급별 점수 구간에 대한 의사결정을 할 때 고려해야 할 것은 ⓐ군집분석 결과를 우선적으로 참고하고, ⓑ직무급 도입을 고려한다면 각 등급별 인원 수를 파악해 직무급 재원이 충분한지를 사전적으로 검토해보아야 한다. 이 모든 사항에 대해 검토가 완료하였다면 과감하게 등급별 구분 기준점이 되는 점수구간을 그어 직무평가등급을 정하면 된다.
'인사 이야기' 카테고리의 다른 글
| [인사-23009] 연관성 규칙(Association Rule)과 경력경로 설계_R언어 (0) | 2023.03.08 |
|---|---|
| [인사-23008] 조직문화, 인사평가 등 HR Survey의 척도와 합리적인 리커트 척도 제안 (0) | 2023.03.01 |
| [인사-23006] 제약조건에 최적화된 교대제 자동 스케쥴링_Python (1) | 2023.02.12 |
| [인사-23005] 직무급 연구 : 직무평가와 군집분석의 활용 ① (0) | 2023.02.05 |
| [인사-23004] 조직몰입 요인 탐색 : 블라인드와 KoBERT AI 활용 (0) | 2023.01.25 |




댓글