
Ⅰ. 보수지급 결정요인이란?

회사는 내부 종업원들에 대하여 "무엇"을 기준으로 보상을 지급할 것인지 결정할 필요가 있다. 이는 보상의 효율성과도 직접적으로 연관되어 있으며, 회사가 지향하고자 하는 구성원들의 업무처리 모습이나 달성하고자 하는 성과와도 관계가 깊다.
가령, 쿠팡, Class 101 등 IT 기반 스타트업과 같이 종업원의 연령이나 학력을 중심으로 보상을 결정하기 보다 그 사람의 업무능력이나 전문성에 근거하여 보상을 책정하고 있다면 그러한 보상체계를 "직능급" 체계라고 한다. 반대로 일반 공공기관의 경우 구성원들의 연령·근속연수 등 연공적인 요소에 의해서 보상이 결정되는 인사제도를 가지고 있는 경우가 많아 "연공급" 성격의 임금체계를 가지고 있다고 볼 수 있다.
결국, 보수지급 결정요인이란 우리 회사에서 직원들에게 무엇을 근거로 그 만큼의 임금을 주는 것인지에 대한 "이유"라고 정의할 수 있다. 이러한 이유는 산업·업종·직군 등 여러 섹터별로 다양하게 존재할 수 있으므로 어떤 것이 가장 타당하다라는 절대불변의 진리는 없다.
여러분의 회사는 "가치있는 인재"를 무엇을 기준으로 정의하고 있습니까?
그러나 구성원들의 조직문화와 조직의 전략과 얼라인되지 않는 보수지급 결정요인은 조직에 해악(害惡)을 낳는다. 가령, 대응해야 하는 상황의 변화속도가 매우 빨라 고정된 직무가 존재하지 않고, 프로젝트 내지 팀 단위 업무가 주된 회사에서 직무급을 채택하는 것은 종업원들의 대응 능력을 떨어트리고 책임 범위를 한정짓게 되어 종국적으로는 소극적 업무수행자를 양산할 가능성이 높다.
그러므로 E-NPS(Employee Net Promoter Score) 등의 기법을 통해 내부 구성원들의 조직행동을 연구하는 노력과 함께 보상체계에 대한 진단을 병행함으로서 종업원들이 가지고 있는 사고와 행동에 대한 체계적인 해석과 이해를 할 수 있어야 한다.
이하에서는 필자가 HR컨설팅을 수행하면서 사용했던 데이터 분석 기법인 의사결정나무(Decision Tree)와 Random Forest를 기반으로 보수지급 결정요인을 진단하는 내용 소개하고자 한다.
Ⅱ. 의사결정나무(DT Analysis)와 랜덤 포레스트(Random Forest)
1. 의사결정나무 분석

의사결정나무는 데이터마이닝 기법 중 하나로서 마케팅 분야에서 가장 널리 활용되고 있는 방법이다. 의사결정나무의 특징은 데이터 내에 존재하는 관계성에 대하여 위와 같은 나무형태로 보기 좋게 분류함으로서 타겟 집단을 세분화하거나 패턴을 예측하는데 활용된다.
의사결정나무는 목표값(범주형·수치형 모두 가능)을 가장 잘 설명하는 변수를 찾아내서 그것을 기준(Node)로 분류하고, 분류된 데이터 내에서 또 다시 목표값을 잘 설명하는 변수를 찾아 분류함으로써 아래로 파생되어 가는 모습을 보여준다. 따라서 분석자의 판단에 따라 ①최소 변화량 수준을 설정하거나 ②노드별 적정 케이스 수를 특정하고, ③최대 트리의 깊이를 지정해줌으로써 무한히 아래로 뻗어나가는 가지를 어느 정도 제한할 필요가 있다.
※ 어느 정도가 적정한지에 대하여 명확한 정답은 없으므로 분석가가 데이터의 시사점을 해석하기 용이한 수준까지 분류가 될 수 있도록 제한을 두면 될 것이다.
의사결정나무를 성장하는 방식은 목표값의 데이터 종류와 분류기준(Gini index, Chi-square statistic, Entrophy index) 따라 ⓐCART 알고리즘, ⓑCHAID 알고리즘, ⓒC5.0 알고리즘으로 분류할 수 있는데 우리가 활용하려는 알고리즘은 CART 알고리즘이다. 그 이유는 R언어가 제공하는 랜덤 포레스트 모델은 레오 브레이먼(Leo Breiman)의 연구논문(2001)에 근거한 것이고, 레오 브레이먼이 만든 랜덤 포레스트 모델은 자신이 개발한 CART 알고리즘을 토대로 작성된 것이기 때문이다.(여기서 활용할 분석 도구는 R언어다.)
※ 사실 3가지 알고리즘 간의 분석결과상의 차이는 그렇게 크지 않다.

위 그림은 실제 모 기업의 의사결정나무분석 결과를 살짝 변형한 결과이다. 여기서 목표값은 수치형 변수로서 "전 직원 임금 총액"으로 설정하고, 설명변수로는 "근속연수, 경력연수, 수행 직무의 가치(직무평가 결과), 연령, 3개년 성과평가점수, 본부, 부서, 성별 등 전 직원 데모그래픽 데이터"로 설정하였다.
분석된 결과는 위에서부터 아래로 해석한다. 해당 기업의 임금은 전체적으로 연령에 기반한 연공급에 가까우나 40세 이상부터는 수행하는 직무가치에 따라 임금이 결정되는 모습을 보여준다. 그리고 수행 직무가치(70점 이상)와 연령(51세 이상)이 높은 직원들은 관리자급으로서 성과책임의 요구정도가 높아짐을 알 수 있고, 그 이하의 사람들은 근속연수와 연령이 한번 더 나타난다는 점에서 연공급의 성격이 강하게 표현된다고 볼 수 있다.
결국 해당 기관은 보직을 수행하는 사람에게는 연공급 + 직무급 + 성과급의 보수지급 결정요인을 가지고 있다고 볼 수 있고, 그 외의 종업원에게는 연공급 + 직무급을 토대로 보수를 지급하고 있다고 볼 수 있는 것이다.
다만, 이러한 의사결정나무의 한계는 일반화가 어려울 수 있다는 점이다. 생각해보라 기업의 인력구조는 각종 사건(Event)들에 의해서 크게 변동할 수 있다. 예를 들어 특정 연도에 정년퇴직하는 종업원들이 몰릴 수도 있고, 혹은 갑자기 사업의 확장으로 인해서 신규 채용을 다른 연도에 비해서 더 많이 할 수도 있다. 이때, 이러한 데이터를 근거로 위와 같은 의사결정나무 분석을 실시하면 왜곡된 결과가 도출될 것이다.
이러한 문제를 해결하기 위하여 랜덤 포레스트 분석(Random Forest)을 추가로 실시하게 되는 것이다.
2. 랜덤 포레스트 분석 : "우리 회사는 '일반적'으로 이것에 의해서 보상을 지급해!"
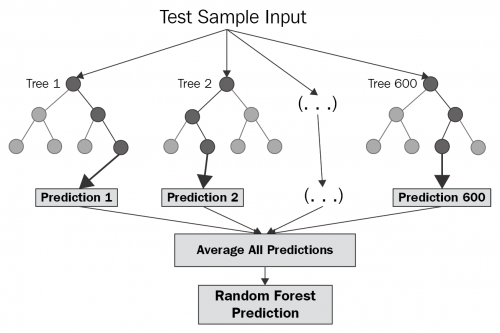
랜덤 포레스트란 학습용 데이터(우리는 진단 목적이므로 구태여 학습용과 실험용을 구분할 필요는 없음)를 랜덤으로 샘플링하여 다수의 의사결정나무를 만들고, 그 결과를 종합함으로서 최종적으로 우리가 설정한 목표값을 가장 잘 설명하는 변수들의 영향력을 계산하는 것을 말한다. 이러한 학습방법을 "앙상블(Ensemble)"이라고도 부른다.
이렇게 설명하니 어렵게 느껴질 텐데 간단하게 생각하면 매우 쉽다. 어떤 주머니에 1000개의 공이 존재한다고 가정해보자. 이 중에서 500개의 공을 임의로 추출하고 이를 그룹 A라 칭하고, 추출했던 500개의 공을 다시 원래 주머니에 돌려놓고 또 500개 공을 새로 뽑아 이를 그룹 B라 칭한다. 이러한 작업을 총 500 ~ 1000회 정도 반복 실시하여 500개에서 1000개 정도의 그룹을 만들어 낸다.
그리고, 각 그룹별로 앞서 설명한 의사결정나무를 만들면 각 500 ~ 1000 그루의 의사결정나무가 만들어지는데, 이를 종합하여 각 설명변수 중 불순도(Impurity)를 감소시키는 정도를 평균(이를 MDI, Mean decrease Impurity라 부른다)으로 계산함으로써 가장 목표값을 잘 설명하는(다른 말로는 잘 분류하는) 설명변수를 도출한다는 것이다.

랜덤 포레스트를 이용하여 위와 같은 MDI를 계산하면 우리 회사가 일반적으로 어떤 기준에 의해서 보상을 결정하고 있는지 알 수 있다. 위 예시 그림에서 살펴보는 바와 같이 해당 기업은 연령이나 근속연수에 근거해서 일반적으로 보상을 지급한다고 볼 수 있다. 이러한 분석 결과는 대한민국 내 대부분의 회사에서 자주 관측되는 결과인데, 이는 대기업 등 국내 기업들이 외부노동시장이나 내부노동시장에서 인력을 공급할 때 채용하고자 하는 공석(직무)에 알맞은 '연령'과 '경력 기간'을 고려하기 때문일 것으로 생각된다. 다만, 스타트업과 같이 신생조직에서는 이러한 경향은 다소 희석될 것으로 기대된다.
만일, 당신의 회사가 지향하고자 하는 보수지급 결정요인이 성과 내지 직무가치(또는 업무량)인데 반하여 연령에 의한 영향력이 지나치게 높게 나오고 있다면 보상체계에 대한 지급기준과 지급방식에 관하여 전반적으로 점검하는 시간이 필요할 것이다.
Ⅲ. R언어를 이용한 분석 방법
1. 의사결정나무
library(rattle) # 의사결정나무 시각화 패키지
library(rpart) # 의사결정나무 패키지
library(caret)
CART_Tree = rpart(보수총액 ~ 설명변수1 + 설명변수2 + 설명변수3 + 설명변수4 + 설명변수5 + 설명변수6, data=Data, maxdepth = 5, method = "anova")
fancyRpartPlot(CART_Tree, split.col="black",nn.col="black",
caption="",palette="Pastel2",branch.col="black",
cex = 0.6, type = 5,
uniform=TRUE) # CART 알고리즘 plot
1. 회사 직원들의 데모그래픽과 임금정보를 담은 데이터 셋을 "Data"라는 이름으로 임포트(Import)
2. 보수총액 데이터는 각종 임금항목을 모두 합친 수치형(연속형) 데이터이자 우리가 분류하고자 하는 목표값임.
3. 목표값이 연속형 데이터이므로 회귀(Regression)나무이므로 method는 "anova"로 설정해 분산의 감소량으로 분류
4. 최대 깊이는 5개까지로 설정하고, 이를 토대로 fancyRpartplot을 이용하여 시각화
5. 시각화 결과가 마음에 안들면 type에 할당된 숫자를 변경하면서 각기 다른 형태의 의사결정나무를 시각화할 수 있음
2. 랜덤 포레스트
library(randomForest)
rf.fit = randomForest(보수총액 ~ 설명변수1 + 설명변수2 + 설명변수3 + 설명변수4 + 설명변수5 + 설명변수6 + 설명변수7 + 설명변수8 + 설명변수9,
data=Data,
mtry = 9, ntree = 500,
importance = T)
varImpPlot(rf.fit, type=2, pch=19, col=1, cex=1, main="Mean Decrease in Impurity")
1. 회사 직원들의 데모그래픽과 임금정보를 담은 데이터 셋을 "Data"라는 이름으로 임포트(Import)
2. mtry의 최대 설정값은 설명변수의 개수인데 일반 HR팀에서 다룰 데이터의 숫자가 그리 크지 않다는 점에서 진단력을 높이기 위해 최대 설정값으로 지정
3. ntree는 앞서 설명한 바와 같이 몇 번정도 데이터 그룹핑을 진행할 것인지를 설정하는 것임, 여기서는 500회 정도로 설정함.
4. importance를 TRUE값으로 설정하여 영향 요인을 발굴하고자 함
5. 이러한 영향요인을 varImpPlot을 이용해 시각화하고 각 설명변수의 중요도 크기를 비교
<참고 문헌>
IT위키, 랜덤 포레스트 : https://itwiki.kr/w/%EB%9E%9C%EB%8D%A4_%ED%8F%AC%EB%A0%88%EC%8A%A4%ED%8A%B8
Mean Decrease Gini :
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=sungmk86&logNo=221204932461
'인사 이야기' 카테고리의 다른 글
| [인사-22010] 조직문화 진단과 블라인드(Blind) 웹 크롤링 1편 (0) | 2022.10.09 |
|---|---|
| [인사-22009] 경력직 신규 채용 시 적정 임금 수준 설정 방법 (0) | 2022.04.30 |
| [인사-22007] D등급 낙인과 상대평가의 함정 (0) | 2022.04.14 |
| [인사-22006] 조직문화 진단과 보상제도 설계 (0) | 2022.03.10 |
| [인사-22005] 임금정책선 설계 방법과 보상의 관점 (0) | 2022.03.01 |




댓글