
Ⅰ. 분석환경 구축하기
웹 크롤링을 하기 위해서는 몇 가지 준비사항이 있다. 먼저 데이터를 수집할 때 사용하는 Interpreter인 ①파이썬(Python)을 다운로드 받아야 하고 이후 이를 활용하기 쉽게 만들어주는 ②통합 개발 환경(IDE)인 Pycharm 혹은 Visual Studio Code 등을 다운로드 받아야 한다.
※ 본 장에서는 파이참(Pycharm)을 기준으로 작성할 예정임.
1. 파이썬 설치하기
우선 파이썬을 설치하여야 하는데 이와 관련해서는 아래의 링크에 아주 자세히 설명되어 있으니 참고하길
바란다.
참고 주소 : https://wikidocs.net/8
2. 파이참 설치하기
파이썬 설치 후 IDE 설치를 위하여 아래의 주소에 접속해 파이참을 다운로드 받아야 한다.
참고 주소 : https://www.jetbrains.com/ko-kr/pycharm/download/#section=windows
(1) 페이지 접속 후 다운로드

우선, 페이지에 접속하여 상단에 보이는 바와 같이 ①번 항목에서 본인의 운영체제를 고르고, ②번에서 Community 버전을 다운로드 받아야 한다.
(2) 설치 진행 중 체크 사항
다운로드를 진행하는 중에 계속해서 다음(Next)을 클릭하다보면 상기 화면이 나타나는데 빨간 네모 점선 박스로 표시된 사항은 반드시 체크하고 하여야 한다.
그 이후 과정은 전부 다음(Next) 혹은 끝마침(Finish)을 선택하면 다운로드는 마무리 된다.
- Create Desktop Shortcut : 바탕화면에 PyCharm IDE 바로가기 생성
- Update context menu : PC 내 임의의 폴더를 마우스 오른쪽 버튼으로 클릭하여 PyCharm에서 프로젝트로 선택한 폴더를 열 수 있도록 함
- Create Associations : PyCharm IDE에서 .py 확장자 파일을 열 수 있도록 함
- Update PATH variable : 명령 프롬프트에서 PyCharm에 직접 접근 가능하게 함
(3) 환경 설정
다운로드가 완료되면 파일을 실행시키고 상기 그림과 같이 New Project를 클릭한다.
새로운 프로젝트를 만들게 되면 복잡한 화면이 나타나는데 거기서 “톱니바퀴” 모양을 클릭하고 Setting 이라는 항목을 선택한다.
(4) 주요 Interpreter 설정
1번에 보이는 것과 같이 Project 명을 클릭하고 그 밑에 Python interperter를 클릭, 이후 2번을 클릭하여 Add local interpreter..를 클릭한다.
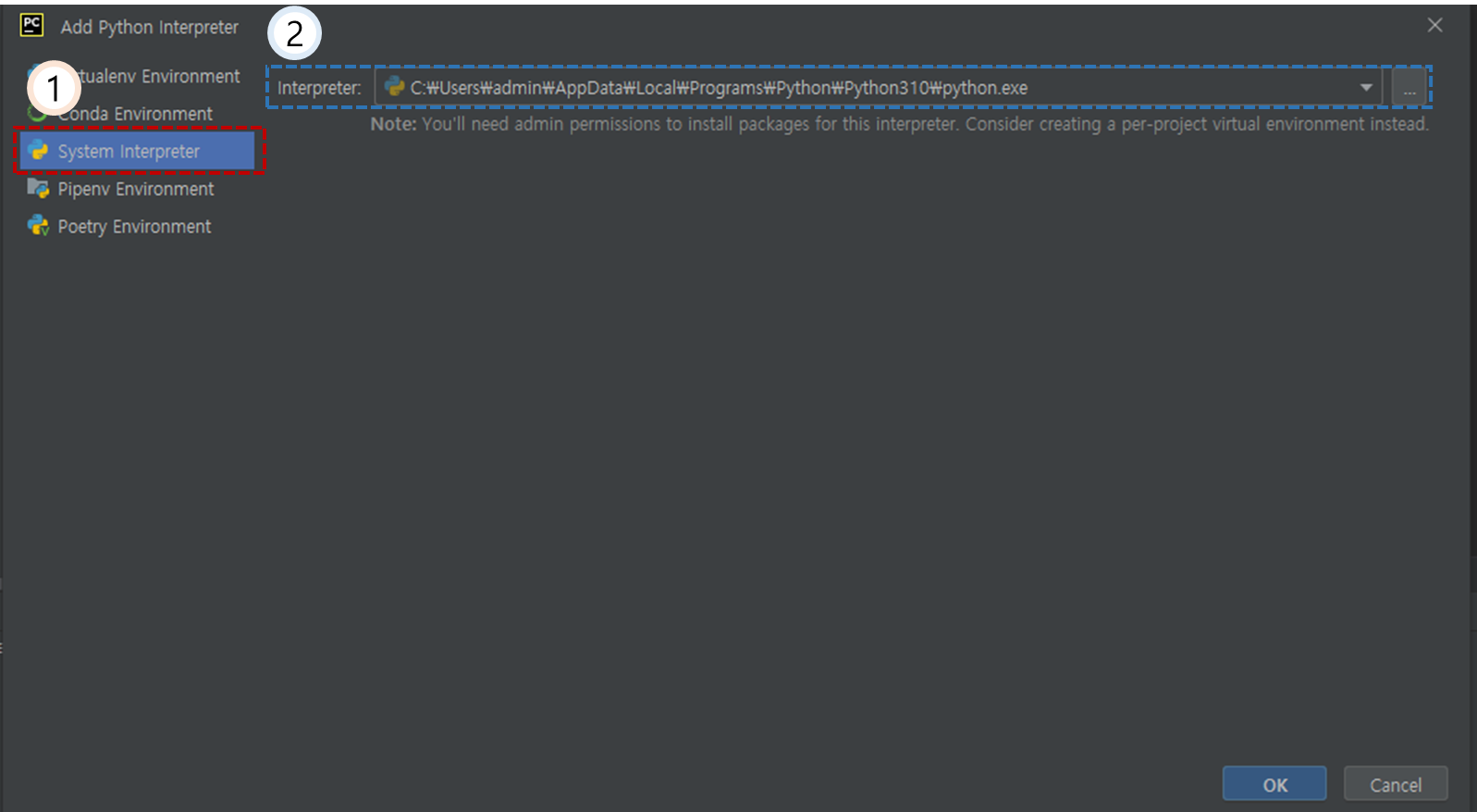
이후 1번 System interpreter 선택한 후 Interpreter 항목을 클릭 후 일전에 다운로드 받은 파이썬을 선택하고 아래 OK 버튼을 클릭한다.
3. 크롤링에 활용될 패키지 다운로드
크롤링을 시작하기 전에 먼저 크롤링을 실행하고 도와줄 패키지를 다운로드 받아야 한다. 물론, 파이썬에서 패키지를 다운로드 할 때 사용하는 코드들이 있으나 해당 코드를 입력했을때 정상적으로 임포트 되지 않는 경우도 종종 있어 그러한 문제를 최소화하는 방안을 아래와 같이 소개하고자 한다.
우선, 크롤링에 필요한 패키지는 다음과 같다.
◎ bs4 : BeautifulSoup을 통해 페이지를 파싱하고 정보를 추출할 때 사용
◎ Selenium : 아래에서 자세히 설명
◎ Pandas : 엑셀과 같은 데이터프레임을 만드는데 활용
※ 우선 bs4를 다운로드 받는 방법을 소개할테니 나머지 패키지는 그대로 따라하면 된다.

① 맨 위 상단에 File을 클릭하고 이후 Setting을 누른다.
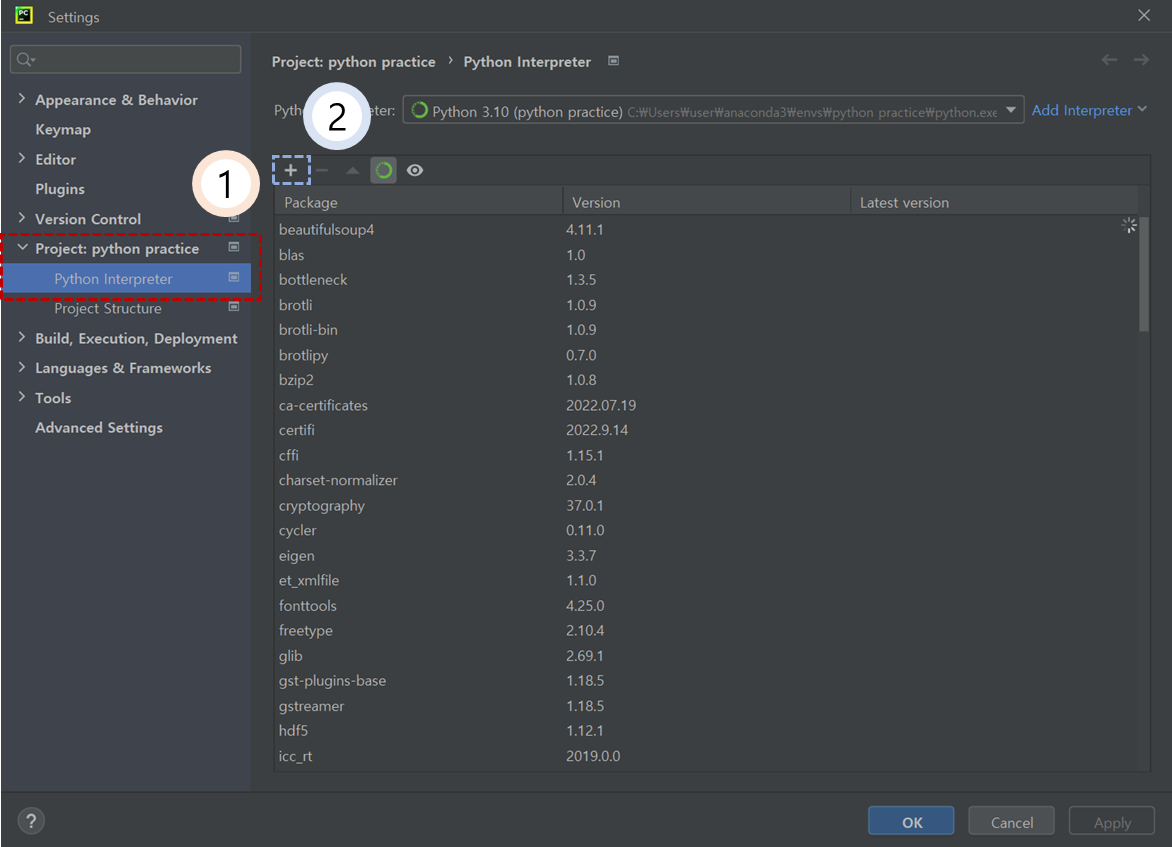
② 이후 상기 그림과 같이 1번을 클릭 후 2번에 나타나 있는 십자가 모양을 클릭한다.
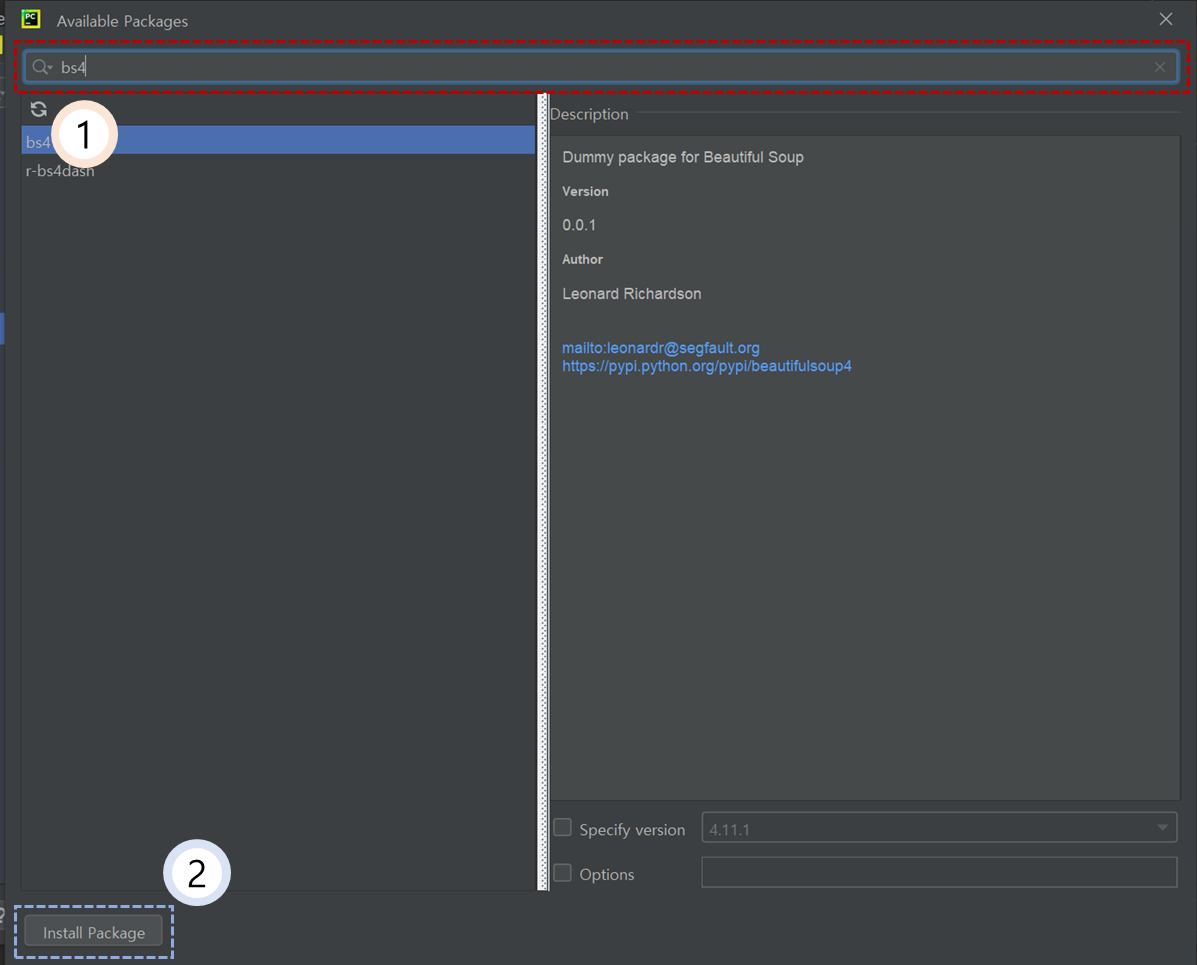
③ 1번 검색창에 “bs4”를 입력한 뒤에 2번 “Install Package”를 클릭한다.
상기 절차를 반복하여 앞서 소개한 패키지를 모두 다운로드 받으면 우리한테 필요한 패키지는 모두 다운로드 받을 수 있다.
4. 크롬 드라이버 설치
셀레니움을 통해서 크롤링을 수행할 것이기 때문에 크롬 드라이버 설치가 필수적이다.
크롬 드라이버는 아래와 같은 순서로 다운로드 받을 수 있다.
① 크롬 버전 확인
② WebDriver 설치
③ chromedriver.exe 추출
먼저 본인의 크롬 버전을 확인해보아야 한다.
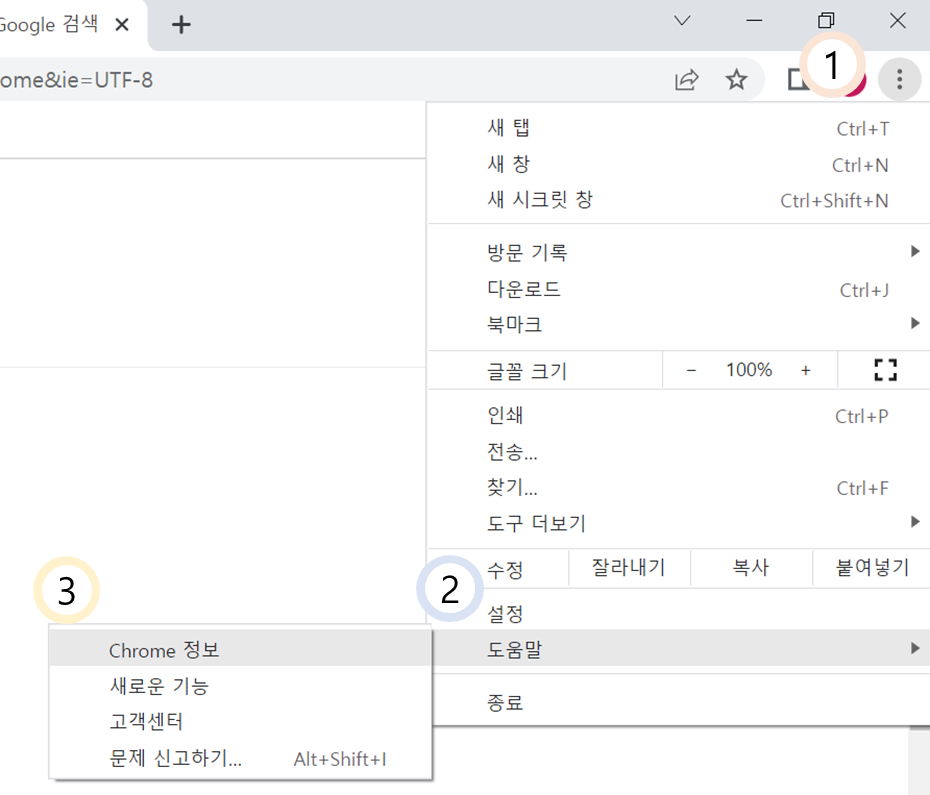
① 먼저, 구글 크롬으로 접속해 오른쪽 상단 1번 항목을 클릭하고 이후 등장하는 항목 중에서 도움말을 클릭한다. 그 다음 3번 항목인 Chrome 정보를 클릭하면 본인이 가지고 있는 크롬의 버전 정보가 나타난다.

② 이후 자신의 크롬 버전과 일치하는 크롬 드라이버를 설치하는 작업을 수행하여야 하므로 아래 주소에 들어가 본인 크롬 버전과 동일 또는 유사한 버전의 드라이버를 클릭한다.
참고주소 : https://chromedriver.chromium.org/downloads
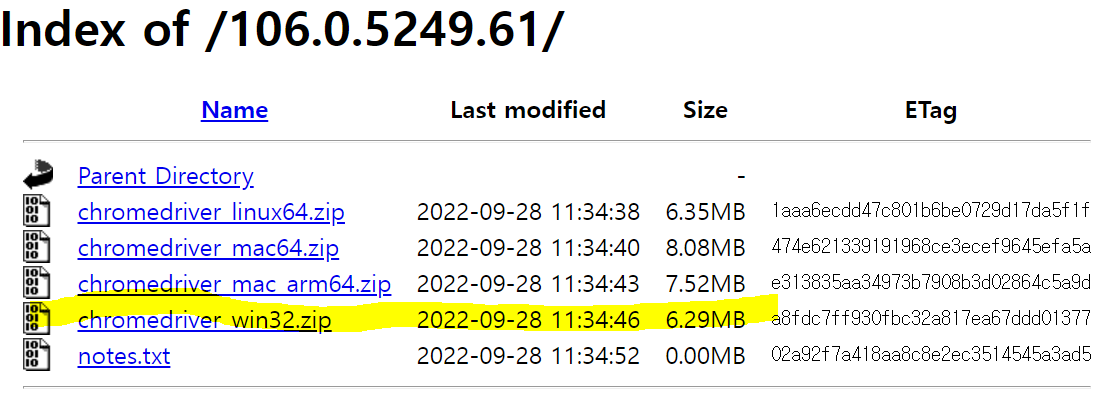
이후 위 그림과 같이 본인의 컴퓨터 운영체제와 동일한 사양의 크롬 드라이버를 다운로드 받으면 2단계는 완료한 것이다.
※ 본인 컴퓨터 사양은 윈도우 64bit 인데 다운로드 가능한 버전이 32bit 밖에 없다면 32bit를 다운로드 받아도 무방하다.

③ 그 다음에는 파이참 내 폴더 항목 중 가장 상단에 위치한 폴더 이름을 선택해 마우스 오른쪽 클릭을 하고(1번), 그 다음 Copy Path를 누른 뒤 Absolute Path를 클릭하면 여러분들의 파이썬 프로젝트 폴더의 위치가 클립보드에 저장된다. 그 다음 메모장을 켜서 붙여넣기 하면 프로젝트 폴더의 위치를 확인한다.
이후 확인한 폴더에 앞서 2단계에서 다운로드 받은 Zip 파일을 압축 해제한 chromewebriver.exe 파일을 넣어주면 크롤링을 위한 모든 준비작업이 완료된다.
Ⅱ. HTML Code와 수집 항목 탐색
1. 셀레니움(Selenium)과 데이터 수집
기초적인 웹 크롤링은 BeautifulSoup이라는 파이썬 라이브러리만으로도 가능할 것이지만 동적 웹페이지에서 생성된 정보는 가져오는데 한계가 있다.
왜냐하면 단순히 서버에 저장된 이미지나 글을 가지고 오는 정적 웹페이지와 다르게 동적 웹페이지는 시간이 경과함에 따라 혹은 접속하는 사람이 누구냐에 따라 게시되는 정보가 달라지기 때문이다.
따라서 이러한 문제를 해결하기 위하여 등장한 도구가 바로 셀레니움(Selenium)이다.
셀레니움은 크롬과 같은 웹 브라우저와 연동하여 실시간으로 변화되는 웹 페이지 소스에서 정보를 추출한다. 그렇기에 여러 웹 크롤링 기법들이 있으나 개인적으로 셀레니움만 알아도 된다고 생각한다.
2. 웹 페이지 HTML 코드 보기
사실 웹 크롤링을 다루기 위해서는 HTML 코드를 어느 정도 알 필요가 있다. 다만 본문에서는 그렇게 비중있게 다루기에는 그 내용이 너무 방대하여 아주 사알짝만 살펴보고 넘어가자!

HTML 코드는 상기 그림과 같은 구조화된 형태를 띄고 있다. 구조화된 형태 때문에 간단하다고 생각되겠지만 우리가 추출하고자 하는 정보는 이러한 구조화된 코드 안에 꽁꽁 숨겨져 있거나 불필요한 내용이나 태그(<body>, <h2>, <head> 등)와 함께 뒤섞여 있는 경우가 많다. 아래 그림처럼 말이다.

그럼 이제부터 본격적인 웹 크롤링을 위하여 여러분들과 세 가지 문제에 대해서 풀어보려고 한다.
①어떻게 하면 저런 뒤죽박죽인 내용을 볼 수 있을까?
②저렇게 뒤죽박죽인 내용 중에서 우리가 필요한 정보는 어디에 있을까?
③필요한 정보를 찾았다면 내가 원하는 위치로 그것만 추출할 순 없을까?
사실 상기 질문 세 가지만 답할 수 있다면 웹 크롤링을 실무상 활용하는데에 크게 문제가 없을 것으로 보인다.
3. 페이지 URL과 웹 페이지 소스 보기
먼저 우리는 분석대상 홈페이지에 접속하여 어떤 내용을 들고올 것인지 살펴볼 필요가 있다. 분석대상 홈페이지는 URL이라는 주소를 가지고 있다.
URL은 페이지가 존재하는 집 주소라고 생각하면 편하다. 우리는 웹 크롤링을 할 때 이러한 집 주소를 이용해 정보를 추출할 것이다. 따라서 URL의 구조를 파악하는 일이 선행되어야 한다.
우선 블라인드에 접속하여 “SPC”라는 기업을 검색해보자
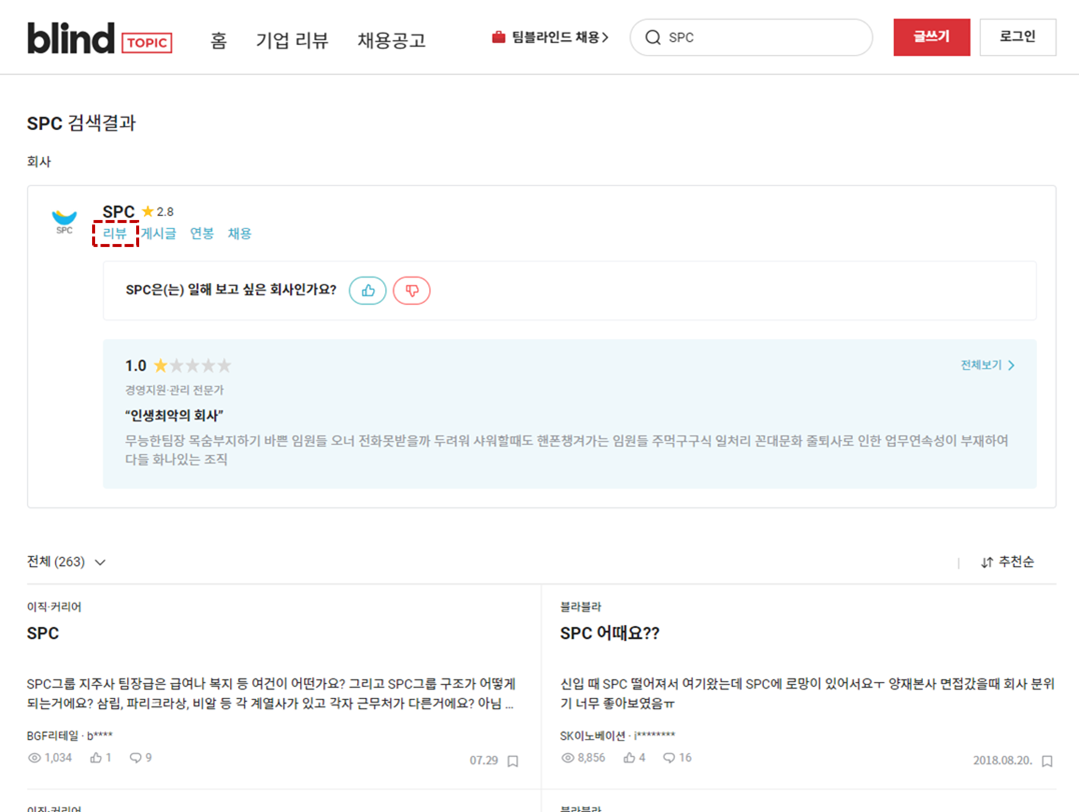
그럼 위와 같은 화면이 나타날 것인데 여기서 붉은색 점선으로 표시한 리뷰를 클릭하고 제일 상단에 인터넷 주소창을 자세히 살펴보라. 이후 리뷰의 2페이지를 클릭하여 다시한번 주소창을 살펴보라. 뭔가 다른 점이 없는가? 다시 1페이지로 뒤로가기 버튼이 아니라 맨 아래 숫자 1을 클릭해 이동해보자.
1페이지 URL = https://www.teamblind.com/kr/company/SPC/reviews?page=1
2페이지 URL = https://www.teamblind.com/kr/company/SPC/reviews?page=2
웹 주소는 이렇게 달라져 있을 것이다. 즉 1페이지는 “page=1”, 2페이지는 “page=2”라고 이해하면된다. 그렇다면 3페이지는? 그렇다 당연히 “page=3”으로 주소 맨 뒷줄에 붙어 있을 것이다.
그렇다면 이번엔 SPC가 아니라 다른 기업을 검색한다고 해보자. 일단 주소창에 아무 기업명이나 입력해보고 똑같이 리뷰창을 띄어본다. 필자는 “삼성전자”를 검색해보았다. 그러자 주소창에서 무엇이 변하였는지 확인해보라.
SPC URL = https://www.teamblind.com/kr/company/SPC/reviews?page=1
삼성전자 URL = https://www.teamblind.com/kr/company/삼성전자/reviews?page=1
중간에 기업명이 달라져있음을 확인할 수 있다. 이것처럼 블라인드의 리뷰 URL은 상당히 이용하기 쉽게 구성되어 있다. 이것을 이해한 상태에서 다음 스텝으로 넘어 가겠다.
이번엔 블라인드 리뷰창을 띄어놓고 F12을 눌러 개발자 도구를 실행시켜보자.
아래와 같은 화면이 나타났다면 붉은색으로 표시해둔 “마우스 모양” 버튼을 클릭하고 추출하고자 하는 정보가 나타난 부분을 클릭해보라.
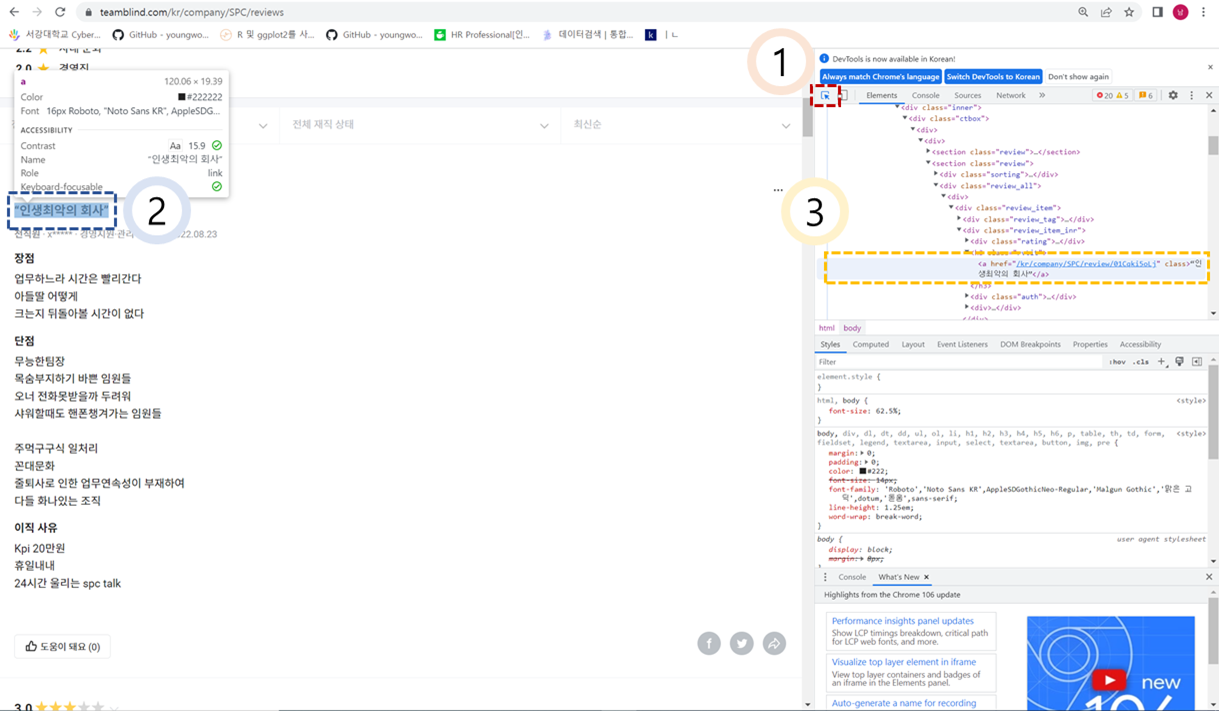
우리가 추출하고자 하는 정보가 HTML코드 내에서 어디에 위치하고 있는지 확인하는 방법이다. 육안으로 위치를 확인하였다면 컴퓨터가 이해할 수 있는 위치를 확인하여야 한다.
컴퓨터가 인식할 수 있는 위치는 태그를 통해서 표현된다. 첫 번째 글의 제목에 붙은 태그는 <h3 class = “rvtit”>이다. 그럼 두 번째 글의 제목에 붙은 태그는 무엇인지 살펴보자. 아까와 동일한 방법으로 살펴보면 두 번째 글 역시도 <h3 class = “rvtit”>라고 표현되어 있는 것을 알 수 있다.
즉, 우리가 필요로 하는 정보는 <h3 class = “rvtit”>라는 태그 안에 위치하고 있는 것이다.
그럼 작성된 글 외에 해당 글이 평가하고 있는 기업 리뷰 점수의 위치를 살펴본다면 아래와 같을 것이다.
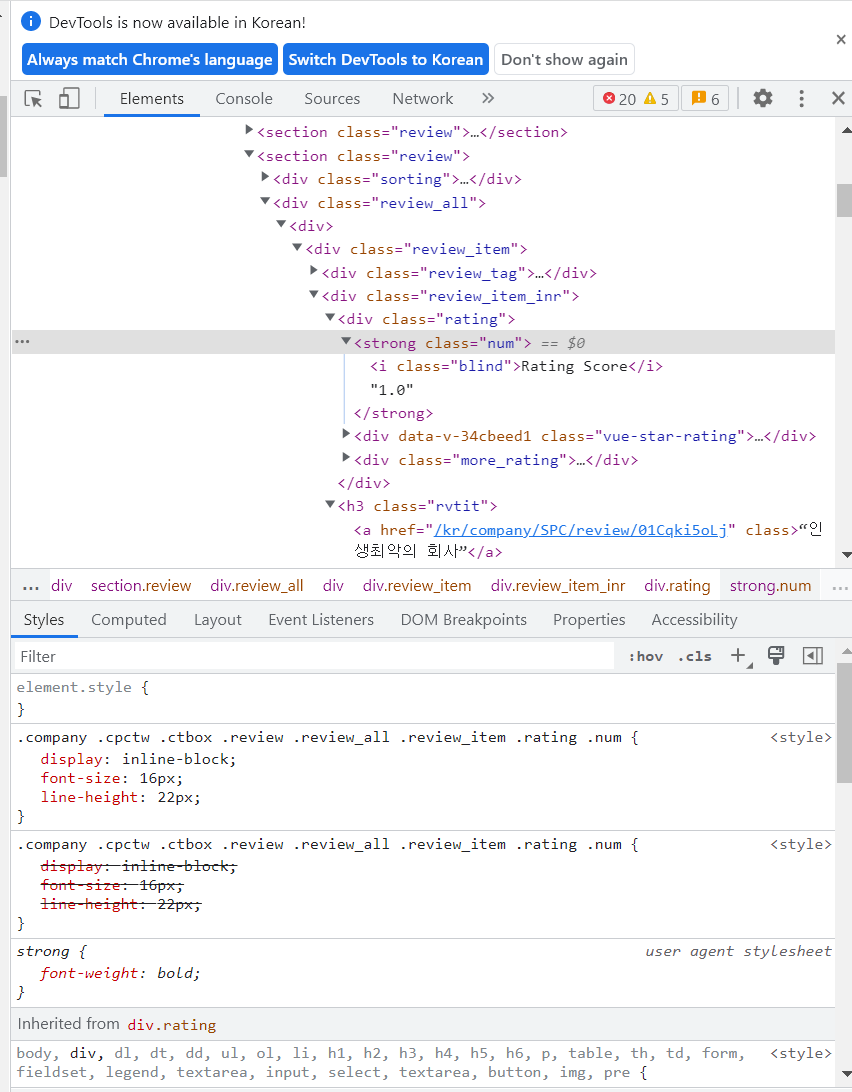
첫번째 글은 기업리뷰 점수가 1점이다. 1점이 기재된 HTML코드 위치는 <Strong class = “num”>이라는 것을 알 수 있다. 이렇게 원하는 정보가 있는 위치를 알고 나면 웹 크롤링의 그 다음 작업을 진행할 수 있다.
Ⅲ. 파이썬 코드와 웹 크롤링
1. 기초 파이썬 코드 학습
사실 본문에서 기초적인 파이썬 코드까지 다루기에는 필자가 너무 벅차기에 이 부분은 독학으로 진행하였으면 한다.
기초적인 파이썬 코드는 사실 시중에 나와있는 서적이나 유투브, 블로그로도 상당히 많은 양을 학습할 수 있으나 간단히 아래 링크에 있는 내용만 학습하더라도 무방할 것으로 본다.
참고주소 : https://wikidocs.net/book/1
2. 사전 준비 진행
파이참을 실행하고 나면 아래 코드를 입력하여 웹 크롤링에 필요한 사전작업을 실시한다.
Packages Import는 앞서 다운로드 받은 패키지를 본 분석 작업에서 활용하겠다고 컴퓨터에게 선언하는 것이라고 보면 된다.
이후 Base URL을 설정하는 작업을 통해 블라인드 사이트 URL 중 일부를 선언한다. 여기서 눈치가 빠른 사람들은 “왜? 데이터를 가져올 것이라면 굳이 완전한 URL이 아닌 URL의 일부만 가져오지?”라는 생각을 하였을 것이다.
일부 URL = https://www.teamblind.com/kr/company/
온전한 URL = https://www.teamblind.com/kr/company/SPC/reviews?page=1
그 이유는 이번에 작성하는 코드는 특정 기업이나 페이지에서의 정보만 추출하는 것이 아니라 여러 기업과 여러 페이지에서 자유롭게 정보를 추출하고자 하기 때문이다. 따라서 ‘기업명’과 ‘페이지 수’와 관련된 URL 정보는 추후에 덧붙여 온전한 URL을 만들려고 하는 것이다. 이후 작성될 파이썬 코드를 보면 어느 정도 이해될 것이다.
Base URL을 작성하였다면 셀레니움이 작동될 구글 드라이버가 실행될 수 있도록 앞서 설치한 chromedriver.exe 실행 명령문을 넣어줘야 한다. 따라서 chromedriver.exe의 위치를 아래 ‘다운로드한 주소’ 안에 입력하면 된다.
사전 준비를 위한 코드가 작성 완료되었다면 작성한 코드를 전부 드래그한 뒤 ALT + Shift + E 키를 눌러 실행시켜주자.
# Packages import
from bs4 import BeautifulSoup
from selenium import webdriver
import pandas as pd
# base url 설정
base = "https://www.teamblind.com/kr/company/"
driver = webdriver.Chrome('다운로드 받은 주소/chromedriver.exe')
3. 크롤링 함수 선언
이제 크롤링을 하기 위한 함수를 만들 것이다.
이 함수는 회사명과 추출하고자 하는 최대 페이지 수를 입력하면 알아서 1페이지에서부터 설정된 최대 페이지 수까지 리뷰의 제목을 추출하는 함수이다.
- for pages ~ try 전까지 : 설정된 최대 페이지까지의 각 페이지별로 HTML코드를 읽어옴.
- try ~ except 전까지 : 앞서 살펴본 <h3 class = “rvitt”> 태그 내 정보(리뷰 글)와 <strong class = “num”> 태그 내 정보(리뷰 점수)를 추출하여 데이터프레임 형식으로 가져옴.
- except ~ break 전까지 : 설정된 페이지가 없는 경우 Null값 표시.
- return : 지금까지 만들어진 리뷰 글과 리뷰점수로 이루어진 데이터프레임을 도출.
※ 무슨 말인지 이해가지 않는 경우라면 그냥 아래 코드를 복사 붙여넣기 하고 실행하여도 무방함.
def getReview (company, num):
review = []
rating = []
for pages in range(0, num):
review_url = base + company + "/reviews?page=" + str(pages+1)
driver.implicitly_wait(10)
driver.get(review_url)
try:
html_doc = driver.page_source
bs_obj = BeautifulSoup(html_doc, "html.parser")
reviews = bs_obj.select("h3.rvtit")
ratings = bs_obj.select("strong.num")
if len(reviews) ==0:
break
else:
for i in range(30):
review.append(reviews[i].text)
rating.append(ratings[i].text)
df = pd.DataFrame((zip(review, rating)), columns=['기업평', '평가점수'])
Data_split = df["평가점수"].str.split('e')
df["평가점수"] = Data_split.str.get(1)
except:
print("null page")
break
return df
4. 크롤링 함수 실행 및 데이터프레임 엑셀로 저장
함수가 만들어졌으면 아래의 코드와 같이 원하는 회사명과 추출하고자 하는 블라인드 리뷰 웹 페이지 수를 입력하면 추출이 자동으로 완료된다.
Data = getReview("한진해운", 3)
Data.to_excel("[운수] 한진해운.xlsx")가령 한진해운이라는 회사를 3페이지만큼 리뷰를 가져오고 싶다면 getReview("한진해운", 3) 이라고 입력하고 이를 Data라는 명칭으로 할당시키고, 이것을 "[운수] 한진해운.xlsx" 이라는 엑셀 파일로 다운로드 받을 수 있는 코드이다.
다운로드 받은 엑셀 파일은 현 프로젝트가 진행 중인 폴더 안에 있다. 만약 못 찾겠다면 컴퓨터 자체 검색 기능을 활용하여 검색해서 찾아낼 수 있다.
Ⅳ. 마무리
지금까지 파이썬을 활용한 웹 크롤링에 대해서 알아 보았다. 해당 기술을 이용하여 실무상 여러가지 일을 수행할 수 있지만, 우리의 본 과제가 HR Analytic이다 보니 조직문화 진단을 위한 재료(데이터)를 수집하는데 적극적으로 사용되었으면 좋겠다.
[인사-22010] 조직문화 진단과 블라인드(Blind) 웹 크롤링 1편
Ⅰ. 조직문화 개선에 대한 뜨거운 관심 최근 기업들에서 사내 문화 개선에 열을 올리고 있는 추세이다. CJ대한통운은 MBTI 실시 후 코칭 북을 지급하는가 하면 의료기기 판매 및 렌탈 업체인 세라
laborlawseok.tistory.com
'인사 이야기' 카테고리의 다른 글
| [인사-23001] 직급체계 설계 방법론 ① : 인사철학을 기반으로 (0) | 2023.01.05 |
|---|---|
| [인사-22012] 조직문화 정의와 그 역사 (0) | 2022.12.25 |
| [인사-22010] 조직문화 진단과 블라인드(Blind) 웹 크롤링 1편 (0) | 2022.10.09 |
| [인사-22009] 경력직 신규 채용 시 적정 임금 수준 설정 방법 (0) | 2022.04.30 |
| [인사-22008] 보상체계 진단① : 보수지급 결정요인 분석 방법론_R언어 (0) | 2022.04.29 |




댓글