

Ⅰ. 감성분석이란?

감성 분석(Sentiment Analysis)은 텍스트에서 나타나는 감정의 극성(긍정적, 부정적, 중립적)을 판단하는 과정이다.(물론, 경우에 따라선 더 다양한 감정으로 분석하는 경우도 있으나 그 실효성에 대해선 다소 회의적이다.) 이는 자연어 처리(Natural Language Processing, NLP), 텍스트 분석, 전산 언어학 등의 기술을 활용하여 수행되는데, 주로 소셜 미디어 모니터링, 브랜드 관리, HR 연구, 시장 트렌드 분석 등에 활용된다.
감성분석의 방법으로는 ⓐ특정 단어와 감성 분류 점수 간의 쌍을 담은 사전(Lexicon) 기반으로 접근하는 방법과 ⓑ컴퓨터가 직접 자료를 통해 배우는 기계학습 모형을 이용하여 접근하는 방법으로 구분된다. ⓐ의 접근법은 상당한 양의 감성용어 사전이 분석 전에 갖춰져야 한다. 영어의 경우 AFINN, Bing, NRC, VADER 등 다양한 종류의 감정들을 내포한 사전이 마련되어 있으나 한국어의 경우 군산대에서 만든 감성사전(KNU) 외에는 특별히 유의미한 사전은 존재하지 않는다.
단순히 사전에 나타난 단어의 빈도수만을 가지고 문장에 나타난 감정을 분석하는 것은 별로 바람직하지 않다고 생각한다. 그도 그럴 것이 그러한 접근법은 문장의 길이와 사용하는 단어의 시기성·폐쇄성(요근래 나오는 줄임말이라던지 특정 연령대에서만 사용하는 은어 등)에 취약하기 때문이다.
따라서 본문에서는 NAVER CLOVA AI를 이용하여 감성분석을 하는 방법을 알아보겠다.
Ⅱ. 활용 데이터 : 블라인드 기업 리뷰
블라인드 기업리뷰를 활용하는 이유는 아래 링크를 통해서 자세하게 설명하였으니 참고해주시기 바란다.
[인사-23004] 조직몰입 요인 탐색 : 블라인드와 KoBERT AI 활용
Ⅰ. 조직의 '진짜' 목소리 : 임금님 귀는 당나귀 귀!! "우리 임금님 귀는 당나귀 귀!!" 어느 날 대나무 숲에서 들려오는 누군가의 외침은 그 나라 임금님의 심장을 뒤흔들고 심기를 불편하게 만든
laborlawseok.tistory.com
이번 분석의 예제는 "엔씨소프트"라는 회사이다. 오늘부터 3년전 리뷰까지 크롤링하였다. 수집된 데이터는 아래 같이 첨부하였다. 아래 파일을 살펴보면 기업리뷰 전체를 발췌하기 보단 리뷰 제목만 추출해서 가져왔다. 그 이유는 NAVER CLOVA AI가 한번 호출할 때 1,000자 이상의 글을 분석할 수 없기 때문이다. 그러나 데이터 모수가 많아 유의미한 시사점을 도출하기에는 부족함이 없을 듯 하다.
이번 주제는 크롤링이 아니기 때문에 데이터 수집에 더 관심이 있으신 분들은 아래에 기재한 파이썬 코드와 링크를 참고하시기 바란다.
※ 기존에 작성했던 블로그 글의 파이썬 코드보다 좀 더 업그레이드한 코드이다.
import sys
from bs4 import BeautifulSoup
from selenium import webdriver
import pandas as pd
import openpyxl
import re
base = "https://www.teamblind.com/kr/company/"
driver = webdriver.Chrome("chromedriver.exe")
df = pd.DataFrame(columns=['기업평', '평가점수', '작성일자']) # 빈 데이터프레임 초기화
date_pattern = r'\d{4}\.\d{2}\.\d{2}' # Regular expression pattern for date in format "YYYY.MM.DD"
def getReview (company, num):
review = []
rating = []
date = [] # 작성일자를 저장할 리스트
for pages in range(0, num):
review_url = base + company + "/reviews?page=" + str(pages+1)
driver.implicitly_wait(10)
driver.get(review_url)
try:
html_doc = driver.page_source
bs_obj = BeautifulSoup(html_doc, "html.parser")
reviews = bs_obj.select("h3.rvtit")
ratings = bs_obj.select("strong.num")
dates = bs_obj.select("div.auth") # 작성일자에 해당하는 CSS selector나 class를 추가하세요
if len(reviews) ==0:
break
else:
for i in range(30):
review.append(reviews[i].text)
rating.append(ratings[i].text)
date.append(re.findall(date_pattern, str(dates[i]))) # 작성일자 추가
df = pd.DataFrame((zip(review, rating, date)), columns=['기업평', '평가점수', '작성일자']) # 작성일자 추가
Data_split = df["평가점수"].str.split('e')
df["평가점수"] = Data_split.str.get(1)
except:
print("null page")
break
return df
Data = getReview("NCSOFT", 1) # 데이터 수집
Data.iloc[:, 2] = Data.iloc[:, 2].astype(str) # 날짜 데이터 데이터 타입 변경
Data.iloc[:, 2] = Data.iloc[:, 2].str.strip('[]') #
Data.to_excel("[IT] NCSOFT.xlsx")
[인사-22011] 조직문화 진단과 블라인드(Blind) 웹 크롤링 2편
Ⅰ. 분석환경 구축하기 웹 크롤링을 하기 위해서는 몇 가지 준비사항이 있다. 먼저 데이터를 수집할 때 사용하는 Interpreter인 ①파이썬(Python)을 다운로드 받아야 하고 이후 이를 활용하기 쉽게 만
laborlawseok.tistory.com
※ 살펴보니 최근 파이참(Pycharm)이 유료화가 된 것으로 확인하였다. 따라서 파이참말고 VS Code라는 IDE를 사용하는 것을 추천드린다.
Ⅲ. NAVER Clova AI 활용 감성분석
1. 분석환경 : Google Colab
Google Colaboratory
colab.research.google.com
이번 분석환경 역시 이전 글과 마찬가지로 Colab에서 진행하도록 한다. 기초적인 사용법은 이전 글 Ⅲ-3-(1) 목차와 Ⅲ-3-(2)에서 모두 설명하였으니 아래 링크를 참고해서 진행하길 바란다.
[노무-23022] '동일노동 동일임금의 원칙' 계량화 방법_Python
Ⅰ. 검토 배경 : KB신용정보 사례와 노동력 가치 비교의 필요성 우리나라 헌법은 누구든지 성별ㆍ종교 또는 사회적 신분에 의하여 정치적ㆍ경제적ㆍ사회적ㆍ문화적 생활의 모든 영역에 있어서
laborlawseok.tistory.com
2. NAVER Clova API 활용 기초

우리가 이번에 활용할 분석도구는 "NAVER CLOVA Sentiment"이다. 이것은 BERT모형에 기반하여 분석을 실시하는데, 문장에서 그러한 감정이 느껴지는 주요 단어나 문구까지 강조해주는 상당히 똑똑한 녀석이다.(심지어 빠르기 까지!)
해당 서비스를 이용하기 위해서는 ①네이버 클라우드 플랫폼 콘솔에 접속하고, ②CLOVA Sentiment 서비스를 활성화한 뒤, ③생성한 Application의 인증정보를 획득함으로써 분석 준비를 마쳐야 한다.
[분석 준비]
①-1 우선, 네이버 클라우드(https://www.ncloud.com/)에 접속한 뒤 우측 상단 Console(콘솔)에 접속
①-2 네이버 로그인을 한 뒤에 맨 왼쪽 바에서 Service 클릭 후 'Sentiment' 검색하여 오른쪽에 나타난 AI·NAVER API 클릭

②-1 상단 Application 등록 버튼 클릭 후 이름을 지정하고, CLOVA Sentiment 선택
②-2 이후 URL 입력란에 아무 URL 입력 후 맨 하단 등록 클릭
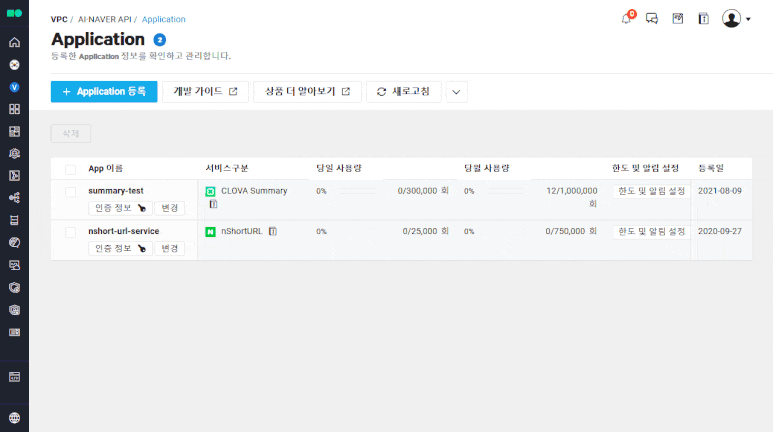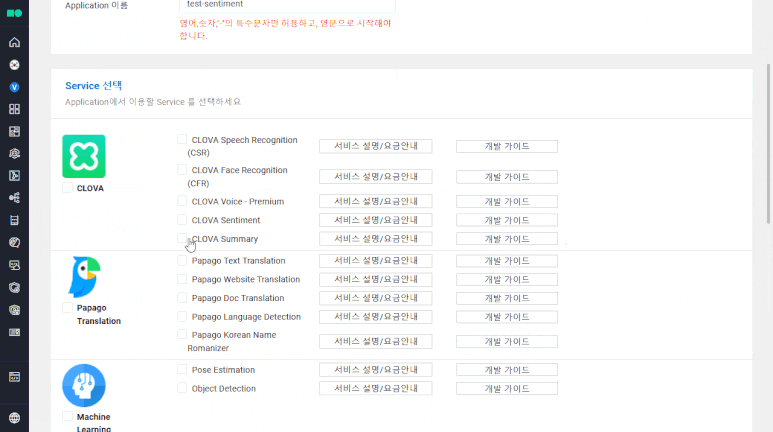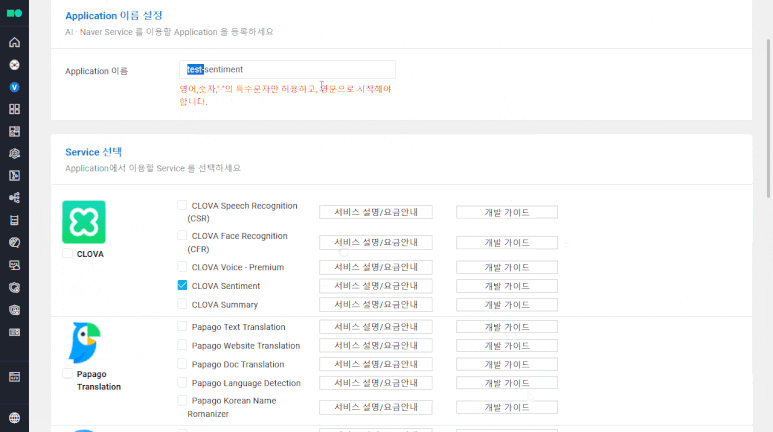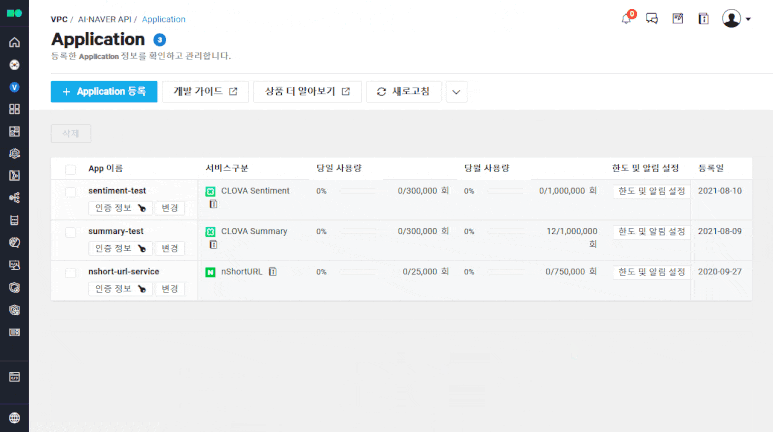
③-1 생성한 어플리케이션의 인증정보를 클릭하여 Client-ID와 Client-Secret 정보를 복사
③-2 복사한 값을 엑셀이나 메모장에 입력 후 보관

3. 파이썬(Python) 코드
(1) 데이터 임포트
## 데이터 입력
import pandas as pd
# 엑셀 파일 경로
excel_file_path = '/content/[IT] NCSOFT.xlsx'
# 엑셀 파일 읽기
df = pd.read_excel(excel_file_path)
# 특정 열 데이터를 리스트로 변환
column_data = df['review'].tolist()우선 앞서 올려드린 파일을 분석환경에 입력해야 한다. 엑셀 데이터를 분석환경에 입력을 하고나면 기업 리뷰만 데이터 프레임에서 추출해 리스트 데이터 구조로 전환시켜야 한다. 전환된 리스트 데이터는 column_data 라는 명칭의 객체에 저장한다.
(2) API 인증정보 입력
#!/usr/bin/env python3
#-*- codig: utf-8 -*-
import sys
import requests
import json
client_id = "yours_id"
client_secret = "yours_secret"
url="https://naveropenapi.apigw.ntruss.com/sentiment-analysis/v1/analyze"
headers = {
"X-NCP-APIGW-API-KEY-ID": client_id,
"X-NCP-APIGW-API-KEY": client_secret,
"Content-Type": "application/json"
}이제 앞서 저장해둔 인증정보를 활용할 차례이다. 엑셀이나 메모장에 저장해둔 Client_id와 Client_secret 코드를 "yours_id"와 "yours_secret"에 복사·붙여넣기한다. 이때 큰 마침표 안에 붙여넣은 정보가 모두 들어가야 한다는 점을 주의해야 한다.
(3) 감성분석 실시
sentiment = []
negative = []
positive = []
neutral = []
for i in column_data:
content = i
data = {
"content": content
}
# API 호출 및 응답 받기
response = requests.post(url, data=json.dumps(data), headers=headers)
rescode = response.status_code
if rescode == 200:
# API 응답을 JSON으로 파싱
parsed_data = response.json()
# sentiment 값 추출
senti = parsed_data['document']['sentiment']
sentiment.append(senti)
# negative, positive, neutral 값 추출
confidence = parsed_data['document']['confidence']
negative.append(confidence['negative'])
positive.append(confidence['positive'])
neutral.append(confidence['neutral'])
else:
print("Error:", response.text)
# 데이터프레임 생성
data = {
'sentiment': sentiment,
'negative': negative,
'positive': positive,
'neutral': neutral
}
df = pd.DataFrame(data)
print(df)이제 앞서 column_data 객체에 저장해둔 기업 리뷰를 하나하나 꺼내어 감성분석을 실시하여야 한다. For문을 이용하여 차례대로 감성분석을 실시할 것이며, 감정분류에 대한 확률정보를 추가로 획득하기 위하여 confidence 내에 각 감정별 확률값을 추출한다.
위 코드를 실행하면 다음과 같은 결과가 도출된다. sentiment 열은 최종적으로 기업리뷰가 어떤 감정으로 분류가 되었는지를 나타내는 것이고, negative, positive, neutral 열은 각각 해당 리뷰에서 느껴지는 감정의 확률이다. 당연히 확률이 1에 가까울 수록 그 감정이 느껴질 가능성이 높다는 것이고, 0에 가까울 수록 그 반대라는 의미이다.

규모가 큰 기업이라면 매년 블라인드 리뷰는 상당한 양이 축적되어 있을 가능성이 높다. 따라서 매년 진행하는 펄스 서베이를 보조·보완하는 도구로 이를 활용해보는 것도 좋을 것으로 보인다.
'인사 이야기' 카테고리의 다른 글
| [인사-23020] 경쟁적 이기주의와 스타하노프 운동 (1) | 2023.11.12 |
|---|---|
| [인사-23019] 업무량 조사와 적정인원 산정 : 정원 관리 (3) | 2023.10.02 |
| [인사-23017] 인사(HR) 관련 개인정보 처리와 방법 (0) | 2023.07.16 |
| [인사-23016] 직무급 도입을 위한 직무분석 방법론 ④ : 본직무분류 (1) | 2023.06.25 |
| [인사-23016] 조직 변화관리 전략과 사회연결망 분석_R언어 (1) | 2023.06.11 |




댓글