◎ 단체교섭이란 노동조합이라는 단결체의 힘을 통하여 사용자 또는 그 단체간에 근로조건의 유지개선 기타 근로자의 경제적․사회적 지위향상을 도모하기 위한 집단적인 교섭을 말함.
◎ 단체교섭은 헌법에서 근로자에게 부여한 노동3권(단결권·단체교섭권·단체행동권) 중 단체교섭권으로부터 인정되는 행위인데, 법원은 "노동 3권은 다같이 존중·보호되어야 하고 그 사이에 비중의 차등을 둘 수 없는 권리들임에는 틀림없지만, 근로조건의 향상을 위한다는 생존권의 존재목적에 비추어 볼 때 위 노동3권 가운데에서도 단체교섭권이 가장 중핵적 권리(대법원 1990. 5. 15. 90도357)"라고 평가한 바 있음.
◎ 근로자들의 생존권 보호라는 목적 아래 단체교섭을 실시하나, 반대로 회사의 입장에서도 단체교섭으로 인하여 향후 기업의 지속가능한 성장 또는 생존을 위한 투자에 사용할 재원이 부족할 수 있어 양자의 입장을 두루 고려한 균형있는 접근이 필요함.
◎ 단체교섭 시 노사 간 대립이 가시화되는 영역은 노동과 자본이 창출한 가치를 어떻게 나누느냐일 것이고, 이는 매년 이루어지는 임금교섭의 형태로 이루어짐. 따라서 우리는 이러한 임금교섭 시 적정한 임금인상률이 어느 정도인지 설정하는 기준이 필요함.
※ 사실, 부스트트랩핑과 같은 복잡한 시뮬레이션 과정을 통해 적정 임금인상률을 뽑아내는 방법도 있으나 이번 글에서는 노무 담당자들이 손 쉽게 접근할 수 있는 여러가지 판단 지표를 제시해보겠음.
Ⅱ. 기업 내부 분석 : 임금인상률 한도 파악
1. 노동생산성 계산의 필요성
◎ 임금인상률을 분해하면 ⓐ인플레이션율과 ⓑ실질 임금인상률로 대별되는데, 인플레이션율은 근로자의 생계비와 연동하여 현재의 삶을 그대로 영속할 수 있도록 한 "유지의 목적"이라면 실질 임금인상률은 실질적으로 근로자의 생활이 인상 이전 시점보다 윤택해질 수 있도록 하는 "보상의 목적"임.
◎ 대부분의 임금교섭에서 노동조합은 생계 유지를 위한 임금인상률을 넘어 보상적 차원의 임금인상률을 요구하는 경우가 많음. 따라서 노동조합의 1차 임금교섭 요구안은 상급단체 교섭 지침을 참고하여 7%~9% 임금인상률로 설정되는 경우가 있음.
양대노총 임금인상률 가이드라인 시계열
◎ 다만 기업은 영리를 추구하는 조직이므로 조직이 달성한 성과(이익, 매출 등)가 근로자의 노동력에서 기인된 것인지 확인할 필요가 있음. 그도 그럴 것이 산업이나 시황 자체가 기업에게 유리하여 노동생산성은 떨어짐에도 불구하고 기업은 이익을 창출하는 때가 있음.
◎회사가 이윤은 창출하였지만 근로자들의 생산성이 이전보다 떨어지거나 유지되었다면 그 원인을 찾아서 제거하는 데에 투자하는 것이 바람직할 것이므로, 단순히 기업 이윤이 창출되었다는 이유만으로 근로자에게 보상 목적의 임금인상분을 지급할 이유는 없음.
2. 노동생산성 : HCVA 및 HCROI
◎ 조직이 달성한 성과와 근로자의 생산성을 비교하는 지표로는 ①HCVA(Human Capital Value Added)와 ②HCROI(Human Capital Return On Investment)가 있음.
HCVA : 종업원 1인당 어느 정도의 부가가치를 창출할 수 있는지 판단 → 계산방식 : 부가가치 ÷ 종업원 수
HCROI : 종업원에게 투입한 인건비의 효율성 → 계산방식 : 부가가치 ÷ 총 인건비
◎ HCVA가 높다면 종업원 개개인이 상당히 높은 부가가치를 창출할 수 있다는 의미이긴 하지만, 이렇게 곧이 곧대로 해석하다간 큰일날 수 있음. 왜냐하면 석유화학·음료제조 등과 같이 산업에 따라 많은 수의 인력이 필요 없는 대신 상대적으로 큰 수익을 얻을 수 있는 회사들이 있기 때문임.
◎ 따라서 매년 HCVA를 계산하여 일종의 시계열 데이터로 관리하고, 이것이 동기 대비 얼마만큼 상승하였는지 혹은 하락하였는지를 계절성(Seasonality)을 제거하여 살펴봄으로서 실질적인 노동력 상승 혹은 생산성 증가가 있었는지 확인해볼 수 있음.
[※ 도와줘요! 이해가 안됩니다! ※]
1. HCVA 시계열 데이터에서 계절성을 제거하는 이유?
HCVA의 분자값인 '부가가치'는 매출액 등과 깊게 연관되어 있다.
회사의 매출은 일정한 주기를 탈 수가 있는데, 가령 아이스크림 판매 회사를 예로 들면 여름의 매출이 높게 찍히고 겨울에는 낮게 찍힐 가능성이 있다.
여름에 매출이 높게 찍혀 다른 계절에 비하여 상대적으로 높은 부가가치를 창출한 것으로 나타나면 HCVA도 오버슈팅하게 되어 마치 여름만 되면 근로자들이 엄청난 성과를 내는 것처럼 왜곡될 수 있다.
따라서 이러한 외생변수(계절, 시장의 주기적인 변화 등)를 제거하기 위하여 계절성(Seasonality)를 제거하고 비교해보는 것이다.
2. 계절성을 제거하는 방법은?
R언어를 이용하면 쉽게 계절성을 계산하고 제거할 수도 있다. 이때, HCVA가 시간이 흐르면 흐를 수록 변동폭이 커지는 것처럼 보인다면 multiplicative model을 선택하고, 그렇지 않다면 additive model을 선택하면 된다.
◎ 만일 생산성이 증가하였다면 그 만큼 임금인상이 정당화될 수 있으므로 보상목적의 임금인상률이 유지 목적의 임금인상률에 가산될 수 있음. 다만, 이러한 방식은 노동경제학 측면에서 지나치게 단순하게 접근하는 것이므로 실제 노사관계에서 적용 시 참고하는 정도로 활용하길 바람.
◎ HCROI는 동종업계와 인건비 지출의 효율성을 비교하는 지표로 활용될 수 있는데, 만일 우리 회사의 HCROI가 동종업계 평균보다 작다면 인건비를 구성하는 여러 항목 중 불필요하다고 판단되는 항목들을 재정비하는 방향으로 단체교섭(안)을 제안해볼 수 있음.
[※ 도와줘요! 그런 자료는 어디서 구해요? ※]
1. 부가가치 계산을 위한 자료는 어디서 구해요?
부가가치액은 가산법에 따르면 상당히 다양한 회계항목들이 필요하다.
가령, ⓐ영업이익, ⓑ영업 외 수익, ⓒ영업 외 비용, ⓓ인건비, ⓔ조세공과 등이 대표적이다.
그러나 회사마다 지출되는 항목들이 다를 수 있어 전문가가 아닌 이상 계산하기 난해할 것이다. -필자도 재무회계 수업을 기피해서 자세히는 모른다 ㅎㅎ
이러한 문제를 해결하기 위해서는 회사 내 재경팀 내지 회계팀의 도움을 받는 방법과 Dart 전자공시시스템에서 자료를 찾아 직접 계산하는 방법이 있다.
Dart 전자공시시스템은 회사가 자신에 관한 감사보고서, 사업보고서, 주주총회 결과 등을 공시하여야 하는 곳이다. → URL : https://dart.fss.or.kr/main.do
비상장 기업이라도 Dart 전자공시시스템에서 검색하여 공시한 자료를 찾아볼 수 있다.
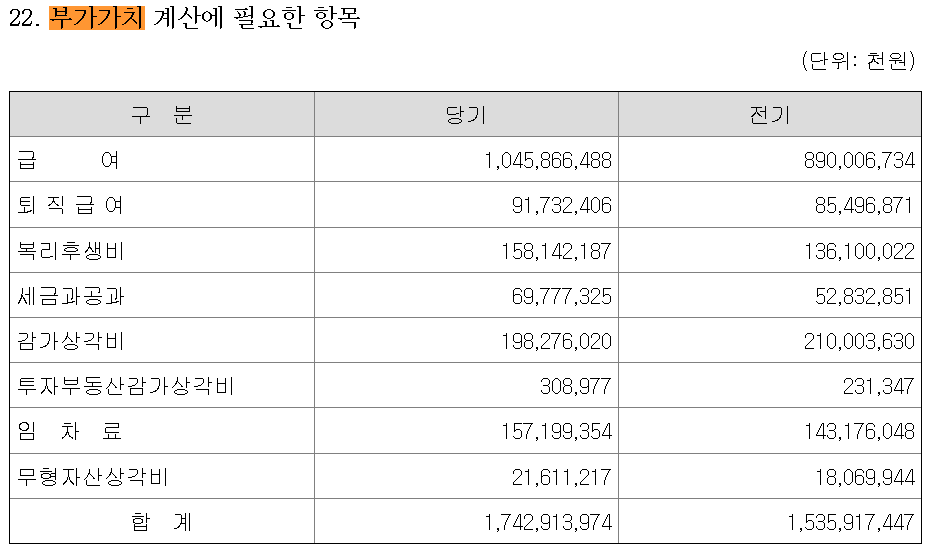
특히 우리가 계산하여야 하는 부가가치액은 감사보고서 내 "주석"을 참고하면 되는데, 별도로 부가가치액을 계산하기 위한 항목들을 한번에 정리해놓은 곳이 있으니 찾아보길 바란다.
(참고) 모 기업 실제 감사보고서 주석 내용
Ⅲ. 기업 외부 분석 _① : 노조 임금 요구 수준 예측
1. 양대노총 및 한국경영자총협회 임금인상률 분석
◎ 한국노총은 매년 2월 말에서 3월 초 "공동임단투 지침"을 통해 적정 임금인상률 수준을 발표하고 있고, 민주노총의 경우 2012년부터 2019년까지 "임금요구안"을 통해 적정 임금인상 수준을 밝혔으나 이후 시점부터는 발표되지 않는 해가 많았음. 한국경영자총협회(이하 "경총"이라 함) 역시 2019년부터는 적정 임금인상률을 밝히고 있지 않음.
◎ 다만, 각 단체가 과거에 적정 임금인상률을 계산할 때 사용하던 기준들이 있으므로 이를 살펴보면 임금인상률 결정 시 참고할 수 있는 시사점을 얻을 수 있음.
◎ 사실 위에서 설명한 여러 경제지표 외에도 양대노총은 ①기업 규모에 따른 임금격차, ②고용형태에 따른 임금격차 등을 조정하기 위하여 "연대임금조성분" 혹은 "저임금노동자 격차 해소 요구분" 요구할 때가 있는데, 이들을 계산하는 공식이나 사용되는 데이터 값이 매번 바뀌기 때문에 이것에 대해서 심각히 고려할 필요는 없을 것으로 사료됨.
◎ 상기 단체들이 적정 임금인상률을 추정하기 위하여 사용하였던 경제지표에 담긴 의미를 분석해보면 ⅰ)경제성장률은 "생산성 증가분", ⅱ)취업자수 증가율은 "노동력 수요의 세기", ⅲ) 물가상승률은 "근로자 생계"를 뜻한다고 볼 수 있음. 이는 임금인상률을 결정하는 이론적인 이야기이긴 하나 노동조합이 없는 사무직 근로자 대상 임금교섭 시 참고할 수 있는 지표들이라 생각됨.
2. 노동조합 최초 임금요구안 예측
◎ 양대노총부터 사용자 단체인 경총까지 임금인상률 결정 시 공통적으로 고려하고 있는 지표가 "경제성장률"과 "물가상승률"임. 이 외에 양대노총은 복잡한 산식으로 표현하고는 있으나 결국 "실질 임금인상률"을 임금인상률에 반영하고자 하는 것으로 파악됨.
※ 노조의 임금교섭 요구 수준을 예측하는 것이므로 경총에서만 고려하는 취업자 증가율은 생략함.
◎ 따라서 우리는 아래와 같은 산식을 통해 노동조합의 임금인상률 수준을 예측해볼 수 있음.
[노동조합 임금인상률 예측 산식]
1차 요구 임금인상률 예측치 = 경제성장률 전망치 + 물가상승률 전망치 + 실질 임금인상률 3~5개년 평균치
◎ 경제성장률 전망치 혹은 물가상승률 전망치는 상당히 다양한 연구기관에서 발표하고 있으므로 내용을 취합하여 최저 수준의 예측치와 최고 수준의 예측치를 둘다 확인해볼 필요가 있음.
2023년 한국노총 공동임단투지침 참고
Ⅳ. 기업 외부 분석 _② :적정 타결 지점 참고
1. 협약임금인상률 개념 및 한계
◎ 협약임금인상률이란 고용노동부가 임금결정현황조사를 통해 매년 2월 또는 7월에 공표하는 지표로서, 상용근로자 100인 이상 사업장에서 임금협약 등을 통해 지급하기로 합의한 임금인상률을 의미함.
◎ 2월에 발표되는 협약임금인상률은 작년 1월부터 당해연도 2월까지의 인상률이고, 7월 말일에 발표되는 협약임금인상률은 당해연도 3월~6월까지의 인상률임. 조사 단위는 월간 또는 연간으로 구분되어 수행되는데 월간 협약임금인상률은 당월분이 아니라 당월까지의 누계분 인상률을 말함.
◎ 협약임금인상률은 민간부문과 공공부문으로 구분되어 조사되는데, 공공부문은 기획재정부의 지침에 의해 통제된다는 점에서 민간부문의 임금인상률을 적정 임금인상률 타결 지점을 설정하는 데에 참고할 필요가 있음.
◎ 적정 임금인상률 타결 지점을 확인하기 위해서 가장 좋은 것은 동종업계의 타결된 임금인상률 현황을 파악하는 것이겠지만 그것이 어렵기 때문에 이러한 보조적인 지표를 참고하여야 함. 다만, 해당 지표는 고용노동부로부터 매월 발표되는 것이 아니라는 점에서 회사의 임금교섭 시점과 해당 조사결과 발표시점과 겹치지 않는다면 활용하기가 다소 어려움.
◎ 따라서 이러한 한계를 극복하기 위하여 시계열 분석을 통해 월별 예측결과를 활용하는 방법을 제안함.
2. 시계열 분석 기법과 예측 : ARIMA 모델 활용
협약임금인상률 시계열 데이터 분해 형태
◎ 협약임금인상률을 예측할 때 사용할 수 있는 시계열 분석기법으로는 ⓐ이동평균법, ⓑARIMA, ⓒVAR 등이 있으나 월별 협약임금인상률의 시계열 데이터의 생김새가 ARIMA(Autoregressive Integrated Moving Average) 모형에 적합하므로 ARIMA 분석을 기반으로 설명을 진행하겠음.
◎ ARIMA는 가장 대표적인 시계열 분석 기법 중에 하나로써 실제 한국노동연구원에서 작성한 『2001년 적정 임금인상률과 임금교섭 전망』이라는 자료에서 이 모형을 통해 적정 임금인상률을 예측할 정도로 검증된 기법임. ARIMA 모형에 대해서 설명하자면 지나치게 복잡하므로 생략하고 바로 실무에 사용할 수 있는 지식을 전달하겠음.
◎ 다운로드 받은 엑셀을 실행시켜 데이터들의 행렬 전환을 실시한 뒤, 필요없는 "총계", "공공부문" 열 데이터는 삭제함.
◎ 그 뒤 해당 데이터를 R에 임포트 시키되 월 데이터를 "01월", "02월" 과 같은 형태로 정리하고, 각각 열 이름을 Month와 임금인상률을 뜻하는 Wage_I로 설정함. 이후 ts() 함수를 이용해 시계열 데이터로 형식을 변환하였음.
◎ 고용노동부의 협약임금인상률 데이터는 2017년 1월 자료가 누락되어 있으므로 해당 결측치를 선형 보간 기법으로 보완하였으며, 데이터를 학습용 데이터 셋(TS_train)과 검증용 데이터 셋(TS_Test)으로 변경함.
(3) 시계열 데이터 적정성 검증
# Stationary Test
summary(ur.df(imputation, type = "none", lags = 10, selectlags = "AIC"))
## 정상성 위반
summary(ur.df(diff(imputation), type = "none", lags = 10, selectlags = "AIC"))
## 1차 차분 정상성 회복
◎ 협약임금인상률 데이터가 시계열 분석에 적합한지 확인하는 절차임. 이때 ADF(Augmented Dicky Fuller) 검정을 사용하여 시계열 데이터 내에 단위근이 존재하는지 확인하게 됨.
◎ 자세한 설명을 하게 되면 모두 도망갈 수 있으므로 분석 결과만 말하자면 협약임금인상률은 단위근이 존재하여 그 자체로는 시계열 분석에 적합한 데이터는 아니였음. 이렇게 단위근이 존재하는 시계열 데이터는 "차분(Difference)"이라는 데이터 변형을 통해 단위근을 없앨 수 있음.
[ur.df함수 실행 결과 해석]
ADF 검정 결과 ADF 검정을 실시하면 상기와 같은 화면이 나타나는데, 복잡하지만 형광팬 칠한 부분만 확인하면 된다.
ADF검정은 단측검정으로서 Value of test-statistic 값이 Critical values 값 보다 왼쪽 또는 오른쪽에 있는지, 즉 Value of test-statistic 값이 Critical values 값보다 작은지 혹은 큰지만 확인하면 된다.
위에서 살펴보면 Critical values가 전부 음수값이고 1pct값이 5pct, 10pct값보다 낮기 때문에 Value of test-statistic 값이 해당 값들보다 낮은지 검정하면 된다.
결과적으로 Value of test-statistic 값이 Critical values보다 낮기 때문에 단위근이 존재하지 않는다고 결론내릴 수 있다.
◎ 실험 결과 민간부분 협약임금인상률은 1차 차분을 통해 시계열 분석에 적합한 형태로 만들 수 있었음. 따라서 이후 ARIMA 분석 시 이러한 점을 참고하여 분석을 실시하여야 함.
(4) 모델 구축 및 잔차 분석
# Modeling
Model_Computer = auto.arima(TS_train, nmodels = 20, d = 1) # 1차 차분 반영
summary(Model_Computer)
Ac_com = accuracy(forecast(Model_Computer, h = 3), TS_Test)
Ac_com # RMSE 값 확인# residuals test
checkresiduals(Model_Computer)
◎ ARIMA 분석은 컴퓨터에게 자동으로 맡기는 방식과 직접 AR값, D값, MA값을 수동 설정하여 모델을 구축하는 방법이 있음. 컴퓨터에게 자동으로 모델을 구축하도록 지시하면 힌드만-칸다카르(Hyndman-Khandakar) 알고리즘을 이용해 AIC(Akaike information criterion)가 가장 낮은 모형으로 예측 모델을 만들어줌.
◎ 보통 컴퓨터에게 모델 구축을 맡기면 실제 Test data와 괴리가 발생하는 경우가 많아 필자는 수동으로 설정하는 방법을 주로 채택하나, 본 단계에서는 독자들이 쉽게 분석에 임할 수 있게 하기 위하여 자동으로 모델을 구축하는 방법을 채택하였음.(auto.arima 이용)
◎ 앞서 차분이라는 데이터 변형이 필요하기 때문에 auto.arima함수 내에 d=1을 기입하였으며, 지나치게 많은 모형을 탐색하는 경우 속도와 예측력이 낮아지는 경우가 있어 탐색할 수 있는 모형의 개수는 20개까지로 제한하였음.
◎ 실제 예측력을 확인하기 위하여 accuracy 함수를 이용해 Test data와 비교한 후 RMSE값을 확인하였음. 해당 모델은 학습용 데이터 셋에서 다소 예측력이 떨어지는 것으로 보이나 테스트 데이터 셋에서는 양호한 예측력을 보여주었음.
※ RMSE는 평균 제곱근 오차라고 부르며 값이 0에 가까울 수록 예측력이 높다고 평가할 수 있음.
◎ 이후 모델 설계 시 놓친 정보가 없는지 확인하는 단계인 "잔차분석" 단계를 거쳐야 함. 잔차분석은 checkresiduals 함수를 통해 실시 가능하며, 실행하게 되면 아래와 같은 분석 결과가 나타남. ACF 그림에서 파란색 선을 초과하는 시차가 없고, 오른쪽 하단 그림에서 잔차값이 정규분포에 가까워진다면 모델의 신뢰구간을 신뢰할 수 있음을 의미함.
◎ checkresiduals 함수를 실행하면 상기 그림 외에도 융-박스(Ljung-Box) 검정 결과를 얻을 수 있는데, 여기 P-value 값이 0.05 이상이라면 자기상관성이 없어 해당 모델이 예측하는데 필요한 정보를 모두 가지고 있음을 의미함. 즉 해당 모델이 예측하는 값을 신뢰할 수 있음을 의미함.
◎ 만일, 예측력 검증과 잔차분석에서 모델이 적합하지 않다면 수동설정을 통해 적합한 모델을 찾아내야 함. 필자 역시 For문을 통해 수 백가지의 경우의 수를 조합해 자동으로 최적 모델을 탐색하는 방법으로 모델을 구축함. 다만, R이 익숙하지 않은 독자들은 이 정도에서 만족하여도 무방함.
(5) 예측 결과 도출과 그래프 작성
# Expetaction & Model Ploting
library(highcharter)
plot_com = forecast(Model_Computer, h = 5, level = 95)
plot_com # 예측값 도출
hchart(plot_com$x, name = "Train Data") %>%
hc_add_series(plot_com$fitted, name = "Auto_ARIMA Fitted Value", color = "red") %>%
hc_add_series(plot_com, name = "Expectation value", color = "green") %>%
hc_add_series(TS_Test, name = "Test Data", color = "black")
◎ forecast 함수를 통해 우리가 만든 모델로 향후 협약임금인상률 값을 예측해볼 수 있음. plot_com을 실행시키면 학습용 데이터 셋을 기반으로 구축된 모델을 통해 5개월 치를 예측한 결과값을 얻을 수 있음.
◎ forecast 함수를 실행시키면 Point Forecast값과 Lo 95, Hi 95값이 나타나는데, Point Forecast는 예측된 특정값을 의미하고 Lo 95와 Hi 95는 예측된 범위를 의미함. 보통 신이 아닌 이상 정확한 예측치를 제시할 순 없으므로 예측된 범위가 함께 주워짐.
◎ Lo 95와 Hi 95 사이값들이 예측범위 값인데, 이는 "95%의 확률로 이 안에서 미래의 값들이 존재할 것이다"라는 의미임. 우리는 이 값들을 참고하여 적정 임금인상률 타결지점을 설정할 필요가 있음.
◎ 보고서 작성용으로 이렇게 예측한 값들을 멋지게 그래프로 표현해볼 수도 있는데, 이때 사용하는 함수가 hchart임. hchart는 highcharter 패키지를 이용해서 만들 수 있음. 아래는 해당 패키지를 통해 작성한 그래프임.
◎ 파란색은 모델을 구축할 때 사용되었던 2011년 ~ 2022년 9월까지의 실제 협약임금인상률 값이고 붉은색 값은 모델을 통해 2011년~2022년 9월까지 예측한 값임. 여기서 중요하게 살펴봐야 할 건, 실제 2022년 10월~12월까지의 Test Data 값과 동일 시점 간 모델이 예측한 값(녹색)이 얼마나 겹치는지임.
◎ 녹색 바탕의 범위는 앞서 살펴본 바와 같이 Lo 95값과 Hi 95값의 범위(95% 범위의 신뢰구간)을 뜻함. 이렇게 하면 모든 시계열 분석 절차가 마무리됨.











댓글