

Ⅰ. 당신은 회사에 대해 어떻게 생각하십니까?
회사의 인사 부서는 조직 내 임직원들의 실제 목소리를 듣기 위하여 다양한 노력을 기울인다. 그러한 노력의 일환으로 공식적인 설문조사에서부터 주니어보드, 노사협의회 등 여러 채널을 통해 직원들의 속내를 파악하려고 한다. 그러나 이러한 의도와는 다르게 대부분의 직원들은 자신의 목소리가 가져올 파급 효과에 대해 두려워 한다.
필자는 직장 내 괴롭힘 신고를 받아 피해자를 돕기 위하여 조심스레 접촉을 하였을 때에도 피해자들은 도대체 자신을 돕기 위해 누가 신고했는지 물어보며 복잡한 마음을 토로하기도 한다. 마치 애증의 관계처럼 자신을 도와주는 것에 대한 감사함과 자신의 속마음을 제3자에게 들어내야 하는 리스크에 노출시킨 것에 대한 복잡한 마음이 고스란히 나타난다.
어느 날 당신에게 당신의 회사에서 이 회사가 어떠한지, 마음에 들지 않는 것은 무엇이며, 현재의 상사에게 만족하는지를 물어본다면 당신은 솔직하게 답변할 수 있는가? 아마도 그럴 수 없을 것이다. 오히려 그러한 질문은 받는 당신은 대체로 긍정적으로 답변할 것이며, 가지고 있는 아픔을 숨길지도 모른다. 많은 회사에서 종업원지원프로그램(EAP)의 일환으로 정신 상담 서비스를 도입하였지만 사용률이 낮은 이유도 그 때문일지 모른다.
그렇기에 우리는 직원들의 진실된 목소리를 포착하기 위하여 비공식적이고 익명성이 보장된 커뮤니티 속 정보들을 활용하여야 한다. 이러한 커뮤니티는 날 것 그대로의 목소리를 담고 있어 때로는 자극적이고 영양가 없는 말뿐으로 착각할 수 있으나, 많은 데이터가 축적되기 때문에 잘만 하면 핵심 트리거 혹은 역린을 발굴해 낼 수 있다.
Ⅱ. 비공식적 커뮤니케이션 채널
1. 비공식적 커뮤니케이션 개념
비공식적 커뮤니케이션은 공식적인 규칙이나 형식을 따르지 않는 커뮤니케이션 방식이다. 보통 직장 내에서 동료들 간의 대화, 친구들 간의 이야기, 이메일이나 문자와 같은 개인적인 소통 방식에서 발생한다. 이러한 커뮤니케이션은 조직의 공식적인 채널을 통해 이루어지는 것이 아니기 때문에, 더 자유롭고 자연스러운 형태를 띠는 경우가 많다.
대표적인 비공식적 커뮤니케이션 채널로는 직장인 익명 소통 채널인 블라인드(Blind)가 있고, 그 밖에도 카카오톡 오픈채팅방이 있다. 노동조합 조직화와 같은 특별한 이슈는 이러한 비공식적인 채널을 통해 구체화되고, 점화될 수 있다는 점에서 회사는 상당히 예의주시하고 관리해야 하는 채널들이라고 볼 수 있다.
LG전자 및 현대자동차 사무직 노조가 만들어지는 배경에도 직장인 익명소통 채널인 "블라인드"가 있었다는 사실과 카카오톡 오픈채팅방이 구심점이 되었다는 점은 부정할 수 없다.
2. 비공식적 커뮤니케이션 특성
비공식적 커뮤니케이션은 직원 간 일상대화를 통해 이루어 지는데, 여기에 익명성이라는 마법의 가루가 더해지는 순간 매우 빠른 정보 공유 체계가 만들어 진다. 그러나 익명성은 다양한 루머를 양산할 수 있다는 점에서 지독한 거짓 소문이 빠르게 회사의 이곳 저곳에 퍼질 수 있다.
따라서 회사는 이러한 커뮤니케이션 채널에서 발생하는 대화 내용에 주목하고, 여기서 직원들이 느끼는 여러 문제점을 빠르게 파악해 대응할 수 있어야 한다. 그러나 비공식적 커뮤니케이션은 정제된 대화라기 보단 일상적인 대화 내용에 해당하고, 형식이나 주제 등이 다채롭기 때문에 그 내용을 정리하는 것이 어려우며, 나아가 데이터의 양도 상당하기 때문에 이것을 일일히 전부 파악하는 것은 매우 어려운 일이다.
Ⅲ. 비공식적 커뮤니케이션 분석 방법
1. 분석 방법 : 의미망 분석(Semantic Network)
일반적으로 단어의 의미는 그 단어가 사용된 문장의 맥락에 따라 다르게 사용된다. 문장을 구성하는 여러 단어들 중 어떤 단어가 동시에 활용되고 있는지를 파악해 그 의미가 전반적으로 어떤 맥락에서 사용되고 있는지를 추정할 수 있게 하는 방법이다.
가령, "개"라는 단어와 "귀여워"라는 단어가 함께 쓰이는 문장에서는 개라는 표현이 긍정적으로 느껴질 수 있지만, "개"와 "아프다" 또는 "피 난다"와 같이 부정적인 내용이 함께 온다면 여기서 사용된 개는 부정적인 맥락에서 사용되었을 가능성이 높다.
특정 회사에 소속되어야 볼 수 있는 블라인드 데이터는 크롤링이 쉽지 않아 데이터 수집이 어려우므로, 이하에서는 데이터 추출이 좀 더 용이한 오픈카톡방의 대화내용을 대상으로 분석을 실시해보도록 하겠다.
2. 데이터 수집 및 전처리
우선 PC 카카오톡을 통해 수집이 필요한 데이터를 담고 있는 오픈채팅방을 열고, 단축기 [Ctrl + S]를 누르면 오픈카톡방에 있는 데이터를 저장할 수 있다. 데이터는 txt 파일로 저장되는데, 해당 파일을 좀더 파악하기 쉽게 바꾸는 작업이 필요하다.
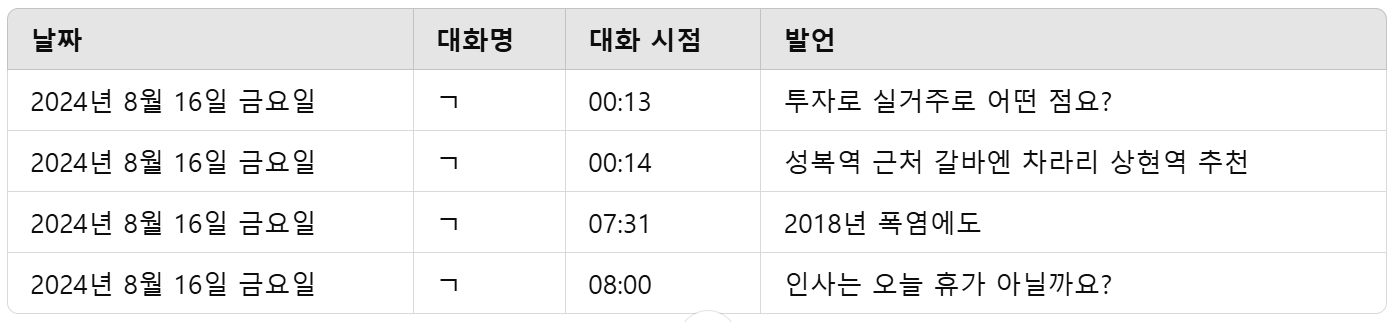
txt 파일을 열어보면 대화의 첫 시작은 날짜가 나타나고, "[대화명] [대화 시점] 발언" 이런 형태로 데이터가 구성되어 있다. 이제 이것을 [날짜] (1열), [대화명] (2열), [대화 시점] (3열), [발언] (4열)로 구성된 프레임에 넣어 엑셀이든 R이든 쉽게 필터링하고 원하는 데이터를 뽑아낼 수 있는 형태로 만들어야 한다.
# 라이브러리 불러오기
library(readr)
library(dplyr)
library(tidyr)
library(stringr)
library(zoo)
# 1️⃣ 텍스트 파일 읽기 (파일 경로 수정 필요)
file_path <- "KakaoTalk_20250309_1300_33_684_group.txt"
lines <- read_lines(file_path)
# 2️⃣ 시스템 메시지 필터링 (입장/퇴장 메시지 삭제)
system_message_pattern <- "님이 (들어왔습니다|나갔습니다)\\."
filtered_lines <- lines[!str_detect(lines, system_message_pattern)]
# 3️⃣ 날짜 행 찾기 (예: "--------------- 2024년 8월 16일 금요일 ---------------")
date_pattern <- "^-+\\s*(\\d{4}년 \\d{1,2}월 \\d{1,2}일 .+?)\\s*-+$"
# 날짜를 동일한 크기로 변환 (NA 유지)
dates <- replace(filtered_lines, !str_detect(filtered_lines, date_pattern), NA)
dates <- str_replace(dates, date_pattern, "\\1") # 날짜만 남기기
dates <- na.locf(dates, na.rm = FALSE) # NA를 직전 값으로 채우기
# 4️⃣ 대화 패턴 찾기 ([대화명] [시간] 발언)
chat_pattern <- "^\\[(.+?)\\] \\[(오전|오후) (\\d{1,2}):(\\d{2})\\] (.+)$"
# 5️⃣ 멀티라인 데이터 복원
cleaned_lines <- c()
current_message <- ""
current_date <- NA
final_dates <- c()
for (i in seq_along(filtered_lines)) {
line <- filtered_lines[i]
if (str_detect(line, date_pattern)) {
current_date <- str_replace(line, date_pattern, "\\1") # 날짜 업데이트
} else if (str_detect(line, chat_pattern)) {
# 새로운 메시지가 시작되면 이전 메시지를 저장
if (current_message != "") {
cleaned_lines <- c(cleaned_lines, current_message)
final_dates <- c(final_dates, current_date) # 날짜 저장
}
current_message <- line # 새로운 메시지 시작
} else {
# 메시지가 이어지는 경우 (빈 줄이 아니면)
if (str_trim(line) != "") {
current_message <- paste0(current_message, " ", str_trim(line))
}
}
}
# 마지막 메시지도 추가
if (current_message != "") {
cleaned_lines <- c(cleaned_lines, current_message)
final_dates <- c(final_dates, current_date)
}
# 6️⃣ 데이터프레임 변환
chat_data <- tibble(line = cleaned_lines, 날짜 = final_dates) %>%
filter(str_detect(line, chat_pattern)) %>%
mutate(
대화명 = str_extract(line, "(?<=^\\[).+?(?=\\])"), # 대화명 추출
period = str_extract(line, "(오전|오후)"), # 오전/오후 구분
time = str_extract(line, "(?<=\\[오전 |\\[오후 )\\d{1,2}:\\d{2}"), # 시간 추출
발언 = str_replace(line, chat_pattern, "\\5") # 발언 내용 추출
) %>%
select(날짜, 대화명, period, time, 발언)
# 7️⃣ 날짜 NA 문제 최종 해결 (한 번 더 NA 채우기)
chat_data$날짜 <- na.locf(chat_data$날짜, na.rm = FALSE)
# 8️⃣ 오전/오후 시간을 24시간 형식으로 변환
chat_data <- chat_data %>%
mutate(
hour = as.numeric(str_extract(time, "\\d{1,2}")),
minute = as.numeric(str_extract(time, "(?<=:)\\d{2}")),
hour = ifelse(period == "오후" & hour != 12, hour + 12, hour), # 오후면 12 추가
hour = ifelse(period == "오전" & hour == 12, 0, hour), # 오전 12시면 0으로 변경
`대화 시점` = sprintf("%02d:%02d", hour, minute) # HH:MM 형식
) %>%
select(날짜, 대화명, `대화 시점`, 발언) # 최종 정리
# 9️⃣ 데이터 확인
print(head(chat_data, 10)) # 상위 10개 데이터 출력
# 🔟 CSV 파일로 저장 (선택)
write_csv(chat_data, "kakao_chat_parsed_cleaned.csv")
이 블로그의 글을 계속해서 읽어본 독자들은 필자가 R이라는 데이터분석 프로그램을 좋아한다는 사실을 알고 있을 것이다. 카카오톡 데이터는 그 양 자체가 무척 방대하기 때문에 엑셀과 같은 복잡한 프로그램보다는 R과 같은 가벼운 프로그램을 활용해야 시간과 컴퓨터 리소스를 효율적으로 사용할 수 있다. 다행히도 R은 무료 프로그램이기 때문에 누구나 사용 가능하니 필자의 아래 블로그 글을 참고하여 다운로드 받아 사용해보길 권한다.
[인사-23007] 직무급 연구 : 직무평가와 군집분석의 활용 ②_R언어
Ⅰ. 분석에 필요한 사항 준비 % ## 실장~팀장급 직무 데이터 준비 filter(str_detect(Job_code, 'D|E')) %>% group_by(Job_code) %>% summarise(Mean_F1 = mean(Factor1), Mean_F2 = mean(Factor2), Mean_F3 = mean(Factor3), Mean_F4 = mean(Factor4)
laborlawseok.tistory.com
앞서 작성한 코드를 R에서 실행하면 다음과 같은 결과가 도출된다. 이로써 분석을 위한 데이터 손질은 대략적으로 마무리된다. 이 다음부터는 분석하고자 하는 방법에 따라 추가적인 데이터 갈무리가 필요할 뿐이다.
3. 월별 의미망 분석
전체 데이터에 대한 의미망을 파악하는 것도 좋지만, 데이터가 지나치게 많아 시간의 흐름에 따른 개별 이슈로 인해 주요 키워드 및 관심사가 희석될 수 있다. 따라서 필자는 카카오톡의 데이터를 월별로 끊어서 내용을 파악하는 것이 그나마 유의미한 데이터 분석이 될 수 있을 것으로 판단하였다.
우선, 날짜 데이터가 우리가 분석하기엔 지나치게 자세하기 때문에 "0000년 00월"의 형태로 표현될 수 있게 바꿔준 뒤, 그 데이터에서 분석하고자 하는 월만 추출해 분석한다. 필자는 예시로 2024년 8월을 분석 대상으로 삼았다.(코드 1번) 만약, 독자들 중에서 다른 월을 분석하고자 한다면 아래 코드 2번 단락의 "2024년 8월"을 분석하고자 하는 월로 바꿔주기만 하면 된다.(코드 2번)
분석 대상 월의 데이터 추출이 완료되면 형태소 분석을 통해 명사, 동사, 형용사를 발굴하고 이를 "단어화(원형화)" 시켜야 한다.(코드 3~4번) 이는 문장에서 단편적인 정보를 추출해 간단한 의미들을 조합해서 해석할 수 있도록 하기 위함이다. 이 작업까지 완료하였다면 추출된 단어들이 어떤 맥락에서 자주 사용되었는지를 파악하여야 한다.(코드 5번) 아시는 바와 같이 단어들이 사용된 맥락을 고려하여 전반적인 의미를 이해하기 위함이다.
마지막으로 함께 사용된 단어들 중 자주 언급되거나 함께 언급된 것들을 연결하는 의미망을 만들어 2024년 8월 대화내용 중 어떤 것이 주요 이슈였고, 이에 대한 직원들의 반응은 어떠하였는지를 확인할 수 있는 그림을 그려야 한다.(코드 6~7번) 참고로 여기서 선택 가능한 연결 방식(Force-directed, K-NN 등)은 결과값에 큰 영향을 미치진 않으므로 아래 내용을 그대로 적용하여도 무방할 것으로 보인다.
# 📌 필요한 라이브러리 불러오기
library(dplyr) # 데이터 처리
library(stringr) # 문자열 처리
library(tidytext) # 텍스트 데이터 분석
library(widyr) # 단어 쌍(pair) 분석
library(tidygraph) # 그래프 데이터 구조
library(ggraph) # 그래프 시각화
# 1️⃣ 날짜 형식을 "YYYY년 M월"로 변환하고, 한글 외 문자 제거 후 정리
chat_data_1 <- chat_data %>%
mutate(
날짜 = str_extract(날짜, "^\\d{4}년 \\d{1,2}월"), # "2024년 8월 16일" → "2024년 8월"
발언 = str_replace_all(발언, "[^가-힣]", " "), # 한글 외 문자(숫자, 특수문자 등) 제거
발언 = str_squish(발언) # 연속된 공백을 하나로 변환
) %>%
select(날짜, 발언) # 날짜와 발언만 남기기
# 2️⃣ "2024년 8월" 데이터만 필터링하고, 불필요한 메시지 제거
M8 = chat_data_1 %>%
filter(날짜 == "2024년 8월") %>% # 2024년 8월 데이터만 선택
mutate(
발언 = str_remove_all(발언, "삭제된 메시지입니다"), # "삭제된 메시지입니다" 제거
id = row_number() # 각 행에 고유 ID 부여
)
# 3️⃣ 형태소 분석을 수행하여 단어별 품사 태깅
M8_comment_pos = M8 %>%
unnest_tokens(input = 발언, # '발언' 열에서 단어 추출
output = word, # 결과를 'word' 열에 저장
token = SimplePos22, # 형태소 분석 방식
drop = F) # 원본 '발언' 열 유지
# 4️⃣ 단어를 분리하고, 동사 및 형용사를 원형으로 변환
M8_pair_1 = M8_comment_pos %>%
separate_rows(word, sep = "[+]") %>% # 복합 명사 및 여러 형태소로 분리
filter(str_detect(word, "/n|/pv|/pa")) %>% # 명사(/n), 동사(/pv), 형용사(/pa)만 필터링
mutate(word = ifelse(
str_detect(word, "/pv|/pa"), # 동사 또는 형용사일 경우
str_replace(word, "/.*$", "다"), # 원형 "다"로 변환 (예: "먹/VV" → "먹다")
str_remove(word, "/.*$") # 명사일 경우 품사 태그 제거
)) %>%
filter(str_count(word) >= 2) %>% # 글자 수가 2개 이상인 단어만 사용
arrange(id) # ID 기준으로 정렬
# 5️⃣ 단어 간 공출현(pairwise count) 계산
M8_pair_2 = M8_pair_1 %>%
pairwise_count(item = word, # 단어별 연결 관계
feature = id, # 같은 발언 ID 내에서 공출현 분석
sort = T) # 빈도수 기준 정렬
# 6️⃣ 네트워크 그래프 생성
M8_graph = M8_pair_2 %>%
filter(n >= 5) %>% # 공출현 횟수가 5회 이상인 단어쌍만 선택
as_tbl_graph(directed = F) %>% # 방향성이 없는 네트워크로 변환
mutate(
centrality = centrality_degree(), # 중심성 계산 (연결 정도)
group = as.factor(group_infomap()) # 그룹(cluster) 할당
)
# 7️⃣ 네트워크 그래프 시각화
ggraph(M8_graph, layout = "fr") + # Force-directed layout 적용
geom_edge_link(color = "gray50", alpha = 0.5) + # 노드 간 연결선 추가 (회색)
geom_node_point(aes(size = centrality, color = group), show.legend = F) + # 노드 크기: 중심성 기준, 색상: 그룹 기준
scale_size(range = c(2, 9)) + # 노드 크기 범위 설정
geom_node_text(aes(label = name), repel = T, size = 4.5) + # 노드 라벨 (단어) 추가, 겹침 방지
theme_graph() # 깔끔한 그래프 스타일 적용
4. 의미망 해석
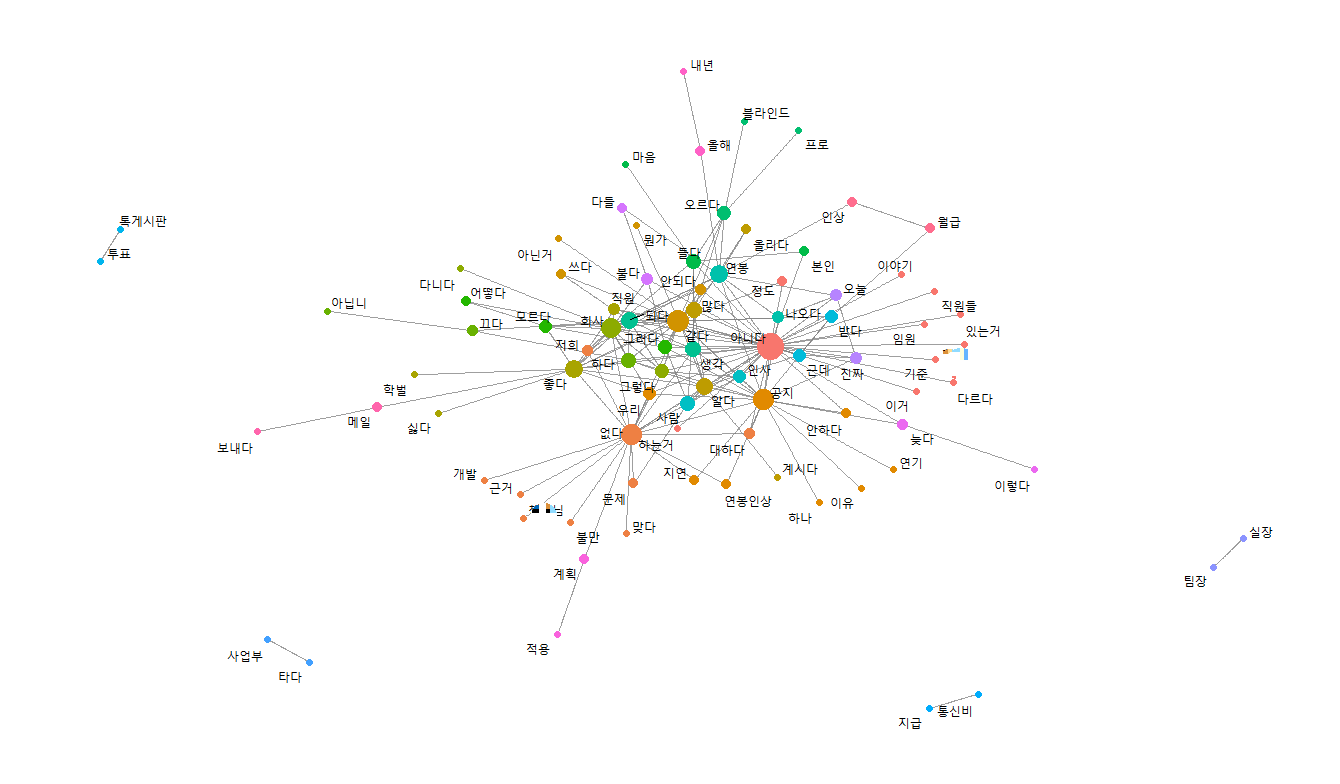
해당 의미망을 살펴보면 2024년 8월에 연봉인상과 관련된 불만이 제기되고 있음을 보여주고 있다. 더 나아가 연봉인상 기준이나 관련 계획이 지연되고 있어 인사조직에 대한 불만이 함께 제기되고 있는 것으로 나타난다. 아래 코드를 실행하면 해당 단어랑 어떤 말이 자주 사용되었는지를 파악할 수 있는데, "공지"라는 단어와 무슨 말이 자주 활용되었는지 확인해본 결과 "없다", "안하다", "지연", "늦다"라는 단어들이 함께 사용되고 있다는 사실을 알 수 있다.
M8_pair_2 %>% filter(item1 == "공지")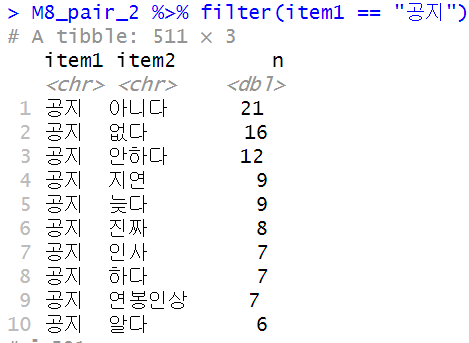
자 이렇게까지 해서 카카오톡 오픈채팅방 대화내용을 분석하는 방법을 알아보았다. 사실 의미망 분석 기법은 텍스트마이닝 기법들 중 하나에 불과하기 때문에 감성분석 등 다양한 방법을 활용하여 더욱 의미있는 직원들의 VOC 수집 및 분석이 가능하다. 다만, 이러한 데이터에 대한 분석 및 활용의 수준은 회사 인사담당 직책자의 데이터 인식 수준에 따라 다르기 때문에 어서 대한민국의 많은 대기업이 HR 데이터 분석에 관심을 가지면 좋을 것 같다.
'인사 이야기' 카테고리의 다른 글
| [인사-24005] 면접(채용)갑질의 원인과 대처 (3) | 2024.07.13 |
|---|---|
| [인사-24004] 직장에서 우리가 상처받는 이유 (1) | 2024.04.21 |
| [인사-24003] 부업·겸직 금지 조항의 현재와 미래 (0) | 2024.03.20 |
| [인사-24002] 반복된 슬로건이 인간 행동과 조직문화에 미치는 영향 (4) | 2024.03.14 |
| [인사-24001] 권력자의 뇌와 직장 내 괴롭힘·성희롱 (1) | 2024.01.21 |




댓글